使用 OTP 构建应用程序
我们已经了解了如何使用通用服务器、有限状态机、事件处理程序和主管。但是,我们还没有真正了解如何将它们组合在一起构建应用程序和工具。
Erlang 应用程序是一组相关的代码和进程。OTP 应用程序专门在其进程中使用 OTP 行为,然后将其包装在一个非常特定的结构中,该结构告诉 VM 如何设置所有内容,然后将其拆卸。
因此,在本章中,我们将使用 OTP 组件构建一个应用程序,但不是一个完整的 OTP 应用程序,因为我们现在不会进行完整的包装。完整 OTP 应用程序的详细信息有点复杂,需要单独的章节(下一章)。本章将重点介绍如何实现一个进程池。这种进程池背后的理念是在通用方式下管理和限制系统中运行的资源。
进程池

是的,池允许限制一次运行的进程数量。池还可以将作业排队,当运行的 worker 数量达到限制时。然后,一旦资源释放,就可以运行这些作业,或者简单地通过告诉用户他们无法执行其他操作来阻塞。尽管现实世界的池与实际的进程池没有什么相似之处,但仍然有理由想要使用后者。其中一些原因可能包括:
- 将服务器限制为最多 N 个并发连接;
- 限制应用程序可以打开的文件数量;
- 通过为某些子系统分配更多资源,而为其他子系统分配更少资源,来为发行版中的不同子系统分配不同的优先级。例如,允许用于客户端请求的进程多于负责为管理层生成报告的进程。
- 允许应用程序在偶尔出现大量负载的情况下保持更稳定的状态,这些负载以突发形式出现,从而在应用程序的整个生命周期内保持更稳定的状态。
因此,我们的进程池应用程序需要支持一些功能:
- 启动和停止应用程序
- 启动和停止特定的进程池(所有池都位于进程池应用程序中)
- 在池中运行任务,如果池已满,则告诉您无法启动任务
- 如果池中有空间,则在池中运行任务,否则,在任务排队时让调用进程等待。一旦任务可以运行,就释放调用者。
- 尽快在池中异步运行任务。如果池中没有空间,则将其排队,并在任何时候运行。
这些需求将有助于推动我们的程序设计。另外,请记住我们现在可以使用主管。当然,我们希望使用它们。问题是,如果它们在健壮性方面赋予我们新的力量,它们也会对灵活性施加一定的限制。让我们探讨一下。
洋葱层理论

为了帮助我们设计一个带主管的应用程序,了解哪些需要监督以及如何监督它们将非常有用。您会想起我们有不同的策略,不同的设置;这些策略适用于不同类型的代码,不同的错误类型。可以犯多种错误!
新手甚至经验丰富的 Erlang 程序员通常难以处理的一件事是,如何应对状态丢失。主管会杀死进程,状态会丢失,真是一件令人痛苦的事情。为了帮助解决这个问题,我们将识别不同类型的状态:
- 静态状态。这种类型可以轻松地从配置文件、另一个进程或重新启动应用程序的主管中获取。
- 动态状态,由可以重新计算的数据组成。这包括您必须从其初始形式转换数据以获得其当前状态的状态
- 无法重新计算的动态数据。这可能包括用户输入、实时数据、外部事件序列等。
现在,静态数据相对容易处理。大多数情况下,您可以直接从主管那里获取它。可重新计算的动态数据也是如此。在这种情况下,您可能希望在 init/1 函数中获取它并进行计算,或者在代码中的任何其他地方进行计算。
最麻烦的类型是无法重新计算的动态数据,您只能祈祷不会丢失它。在某些情况下,您会将这些数据推送到数据库,尽管这并不总是好的选择。
洋葱层系统的理念是允许所有这些不同的状态通过隔离不同类型的代码相互隔离来得到正确的保护。这是进程隔离。
静态状态可以由主管、启动系统等处理。每次子进程死亡时,主管都会重新启动它们,并可以为它们注入某种形式的静态状态,始终可用。由于大多数主管定义本质上是相当静态的,因此您添加的每一层监督都充当一层保护应用程序免受其故障和状态丢失的盾牌。
可重新计算的动态状态有很多可用的解决方案:从主管发送的静态数据构建它,从其他进程、数据库、文本文件、当前环境或其他任何地方获取它。在每次重新启动时,获取它应该相对容易。您有主管可以执行重新启动工作的事实,足以帮助您保持该状态处于活动状态。
无法重新计算的动态类型需要更加谨慎的方法。洋葱层方法的真正本质在这里体现出来。理念是最重要的数据(或最难找回的数据)必须是受保护程度最高的类型。您实际上不允许出现故障的地方称为应用程序的错误内核。

错误内核可能是您最需要使用 try ... catch 的地方,在处理异常情况至关重要的地方。这是您想要保持无错误的地方。必须对周围进行仔细的测试,尤其是在无法回溯的情况下。您不希望在处理订单的过程中丢失客户的订单,对吧?某些操作将被认为比其他操作更安全。因此,我们希望将重要数据保存在最安全的核心,并将所有危险的东西保存在核心之外。具体来说,这意味着所有相互关联的操作都应属于同一个监督树,而无关的操作应保存在不同的树中。在同一个树中,容易出错但不太重要的操作可以放在一个单独的子树中。如果可能,只重新启动需要重新启动的树的一部分。在设计实际进程池的监督树时,我们将看到一个例子。
池的树
那么,我们应该如何组织这些进程池呢?这里有两种思路。一种告诉人们自下而上设计(编写所有单独的组件,按需将它们放在一起),另一种告诉我们自上而下编写(设计好像所有部分都存在,然后构建它们)。这两种方法同样有效,具体取决于情况和您的个人风格。为了便于理解,我们将在这里自上而下地执行操作。
那么,我们的树应该是什么样子呢?我们的要求包括:能够启动整个池应用程序,拥有多个池,每个池都有多个可以排队的 worker。这已经暗示了一些可能的设计约束。
每个池都需要一个 gen_server。服务器的任务是维护池中 worker 数量的计数器。为了方便起见,同一个服务器还应保存任务队列。那么,谁应该负责监督每个 worker 呢?是服务器本身吗?
用服务器来做很有趣。毕竟,它需要跟踪进程来统计它们,而自己监督它们是一种巧妙的方式。此外,服务器和进程都不能在不丢失其他所有进程的状态的情况下崩溃(否则,服务器在重新启动后无法跟踪任务)。它也有一些缺点:服务器承担了太多责任,可能被认为更加脆弱,并且重复了现有、经过良好测试的模块的功能。
确保所有 worker 都得到妥善处理的最佳方法是为它们使用主管。
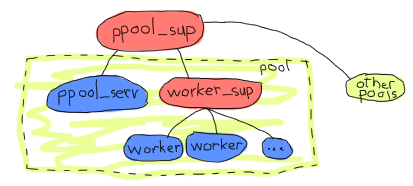
例如,上面的主管将为所有池使用一个主管。实际上,每个池都是一组池服务器和 worker 主管。池服务器知道其 worker 主管的存在,并要求它添加项目。鉴于添加子进程是一件非常动态的事情,并且到目前为止其限制尚不清楚,因此应使用 simple_one_for_one 主管。
注意:选择 ppool 这个名字是因为 Erlang 标准库中已经存在 pool 模块。此外,它也是一个糟糕的与池相关的双关语。
这样做的优点是,由于 worker_sup 主管只需要跟踪单一类型的 OTP worker,因此保证每个池都与特定类型的 worker 相关联,并具有简单易定义的管理和重启策略。这里就是一个更好地定义错误内核的例子。如果我正在使用一个用于 Web 连接的套接字池和另一个负责日志文件的服务器池,那么我正在确保日志文件部分的应用程序中的错误代码或混乱的权限不会淹没负责套接字的进程。如果日志文件池崩溃太多,它们将被关闭,并且其主管将停止。哦,等等!
是的。由于所有池都在同一个主管之下,因此在短时间内重新启动特定池或服务器太多次会导致所有其他池停止。这意味着我们可能想做的是添加一层监督。这将使处理多个池变得更加简单,因此假设我们的应用程序架构如下:
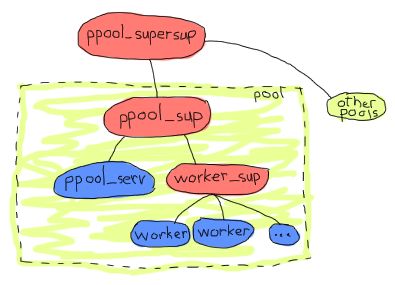
这样更有意义。从洋葱层的角度来看,所有池都是独立的,worker 之间也是独立的,ppool_serv 服务器将与所有 worker 隔离。这对于架构来说已经足够了,我们需要的似乎都已到位。我们可以开始进行实现,再次从上到下。
实现主管
我们可以从顶层主管 ppool_supersup 开始。它所要做的只是在需要时启动池的主管。我们将为它提供一些函数:start_link/0,它启动整个应用程序,stop/0,它停止应用程序,start_pool/3,它创建特定的池,以及 stop_pool/1,它执行相反的操作。我们也不能忘记 init/1,它是主管行为所需的唯一回调
-module(ppool_supersup).
-behaviour(supervisor).
-export([start_link/0, stop/0, start_pool/3, stop_pool/1]).
-export([init/1]).
start_link() ->
supervisor:start_link({local, ppool}, ?MODULE, []).
在这里,我们将顶级进程池监督者命名为ppool(这解释了{local, Name}的使用,这是一个关于在节点上注册gen_* 进程的OTP约定;另一个用于分布式注册)。这是因为我们知道每个Erlang节点只有一个ppool,并且我们可以给它一个名字,而不用担心冲突。幸运的是,同一个名字可以用来停止整个进程池集合。
%% technically, a supervisor can not be killed in an easy way.
%% Let's do it brutally!
stop() ->
case whereis(ppool) of
P when is_pid(P) ->
exit(P, kill);
_ -> ok
end.
正如代码中的注释解释的那样,我们无法优雅地终止监督者。原因是OTP框架为所有监督者提供了一个定义良好的关闭过程,但我们现在无法从当前位置使用它。我们将在下一章看到如何做到这一点,但现在,强行杀死监督者是我们能做的最好的方法。
什么是顶级监督者?嗯,它的唯一任务是将进程池保存在内存中并监督它们。在本例中,它将是一个无子进程的监督者。
init([]) ->
MaxRestart = 6,
MaxTime = 3600,
{ok, {{one_for_one, MaxRestart, MaxTime}, []}}.
现在,我们可以专注于启动每个单独进程池的监督者,并将它们附加到ppool。根据我们的初始要求,我们可以确定我们需要两个参数:进程池将接受的worker数量,以及worker监督者启动每个worker所需的{M,F,A}元组。为了更好地衡量,我们还会添加一个名称。然后,我们在启动进程池的监督者时,将这个childspec传递给它。
start_pool(Name, Limit, MFA) ->
ChildSpec = {Name,
{ppool_sup, start_link, [Name, Limit, MFA]},
permanent, 10500, supervisor, [ppool_sup]},
supervisor:start_child(ppool, ChildSpec).
您可以看到每个进程池的监督者都被要求是永久性的,并且拥有必要的参数(注意我们是如何将程序员提交的数据转换为静态数据的)。进程池的名称既传递给监督者,也用作child specification中的标识符。还有一个最大关闭时间为10500。没有简单的方法来选择这个值。只要确保它足够大,以至于所有子进程都有时间停止。根据您的需要进行调整,测试和调整。如果您不确定,也可以尝试使用infinity选项。
要停止进程池,我们需要请求ppool超级监督者(超级监督者!)杀死其匹配的子进程。
stop_pool(Name) ->
supervisor:terminate_child(ppool, Name),
supervisor:delete_child(ppool, Name).
这是可能的,因为我们给进程池的Name作为childspec标识符。太好了!现在我们可以专注于每个进程池的直接监督者!
每个ppool_sup将负责进程池服务器和worker监督者。
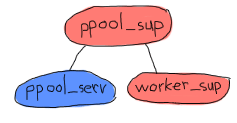
你看到这里有趣的地方了吗?ppool_serv进程应该能够联系worker_sup进程。如果我们要让它们在同一个时间由同一个监督者启动,我们将无法让ppool_serv知道worker_sup,除非我们使用supervisor:which_children/1做一些技巧(这会对时间敏感,而且有一定风险),或者给ppool_serv进程(以便用户可以调用它)和监督者都起一个名字。现在我们不想给监督者起名字,因为
- 用户不需要直接调用它们。
- 我们需要动态生成原子,这让我感到不安。
- 有一个更好的方法。
方法基本上是让进程池服务器动态地将worker监督者附加到它的ppool_sup。如果这很模糊,您很快就会明白。现在,我们只启动服务器。
-module(ppool_sup).
-export([start_link/3, init/1]).
-behaviour(supervisor).
start_link(Name, Limit, MFA) ->
supervisor:start_link(?MODULE, {Name, Limit, MFA}).
init({Name, Limit, MFA}) ->
MaxRestart = 1,
MaxTime = 3600,
{ok, {{one_for_all, MaxRestart, MaxTime},
[{serv,
{ppool_serv, start_link, [Name, Limit, self(), MFA]},
permanent,
5000, % Shutdown time
worker,
[ppool_serv]}]}}.
就是这样。请注意,Name被传递给服务器,以及self(),即监督者自己的pid。这将使服务器能够调用worker监督者的生成;MFA变量将用于该调用,以让simple_one_for_one监督者知道要运行哪种worker。
我们将了解服务器如何处理所有事情,但现在,我们将通过编写ppool_worker_sup来完成应用程序所有监督者的编写,该监督者负责所有worker。
-module(ppool_worker_sup).
-export([start_link/1, init/1]).
-behaviour(supervisor).
start_link(MFA = {_,_,_}) ->
supervisor:start_link(?MODULE, MFA).
init({M,F,A}) ->
MaxRestart = 5,
MaxTime = 3600,
{ok, {{simple_one_for_one, MaxRestart, MaxTime},
[{ppool_worker,
{M,F,A},
temporary, 5000, worker, [M]}]}}.
很简单。我们选择了simple_one_for_one,因为worker的数量可能会非常多,而且需要速度,另外我们还想限制它们的类型。所有worker都是临时的,因为我们使用{M,F,A}元组来启动worker,所以我们可以在那里使用任何类型的OTP行为。

使worker成为临时的原因有两个。首先,我们无法确定在发生故障的情况下是否需要重新启动它们,或者需要对它们使用哪种重新启动策略。其次,进程池可能只有在worker的创建者可以访问worker的pid的情况下才有用,具体取决于用例。为了以任何安全和简单的方式做到这一点,我们不能随意地重新启动worker,而没有跟踪其创建者并向其发送通知。这将使事情变得非常复杂,仅仅为了获取一个pid。当然,您可以自由地编写自己的ppool_worker_sup,它不返回pid,而是重新启动它们。这种设计本身并没有错。
处理worker
进程池服务器是应用程序中最复杂的部分,所有巧妙的业务逻辑都在这里发生。以下是对我们必须支持的操作的提醒。
- 在池中运行任务,如果池已满,则告诉您无法启动任务
- 如果进程池有空闲位置,则在进程池中运行任务,否则让调用进程等待,直到任务在队列中,直到它可以运行。
- 尽快在池中异步运行任务。如果池中没有空间,则将其排队,并在任何时候运行。
第一个将由名为run/2的函数完成,第二个由sync_queue/2完成,最后一个由async_queue/2完成。
-module(ppool_serv).
-behaviour(gen_server).
-export([start/4, start_link/4, run/2, sync_queue/2, async_queue/2, stop/1]).
-export([init/1, handle_call/3, handle_cast/2, handle_info/2,
code_change/3, terminate/2]).
start(Name, Limit, Sup, MFA) when is_atom(Name), is_integer(Limit) ->
gen_server:start({local, Name}, ?MODULE, {Limit, MFA, Sup}, []).
start_link(Name, Limit, Sup, MFA) when is_atom(Name), is_integer(Limit) ->
gen_server:start_link({local, Name}, ?MODULE, {Limit, MFA, Sup}, []).
run(Name, Args) ->
gen_server:call(Name, {run, Args}).
sync_queue(Name, Args) ->
gen_server:call(Name, {sync, Args}, infinity).
async_queue(Name, Args) ->
gen_server:cast(Name, {async, Args}).
stop(Name) ->
gen_server:call(Name, stop).
对于start/4和start_link/4,Args将是传递给{M,F,A}三元组中的A部分的附加参数。请注意,对于同步队列,我已经将等待时间设置为infinity。
如前所述,我们必须从服务器内部启动监督者。如果您正在添加代码,您可能希望包含一个空的gen_server模板(或使用已完成的文件)以便跟踪,因为我们将按功能进行操作,而不是从头到尾地阅读服务器。
我们首先做的是处理监督者的创建。如果您还记得上一章关于动态监督的内容,我们不需要为需要添加少量子进程的情况使用simple_one_for_one,因此supervisor:start_child/2应该可以做到。我们首先定义worker监督者的child specification。
%% The friendly supervisor is started dynamically!
-define(SPEC(MFA),
{worker_sup,
{ppool_worker_sup, start_link, [MFA]},
temporary,
10000,
supervisor,
[ppool_worker_sup]}).
没什么特别的。然后我们可以定义服务器的内部状态。我们知道我们需要跟踪一些数据:可以运行的进程数量,监督者的pid以及所有作业的队列。为了知道worker何时完成运行以及从队列中获取一个worker来启动它,我们需要从服务器跟踪每个worker。这样做的明智方法是使用监控器,因此我们还会在状态记录中添加一个refs字段,以便将所有监控器引用保存在内存中。
-record(state, {limit=0,
sup,
refs,
queue=queue:new()}).
有了这个准备,我们可以开始实现init函数。自然的想法是如下所示
init({Limit, MFA, Sup}) ->
{ok, Pid} = supervisor:start_child(Sup, ?SPEC(MFA)),
link(Pid),
{ok, #state{limit=Limit, refs=gb_sets:empty()}}.
然后继续。但是,这段代码是错误的。使用gen_*行为的方式是,生成行为的进程会等待,直到init/1函数返回才会恢复其处理。这意味着,通过在其中调用supervisor:start_child/2,我们创建了以下死锁。
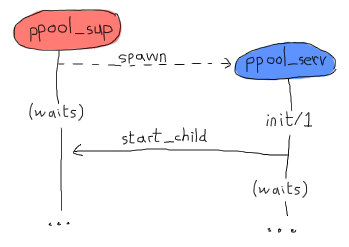
这两个进程将一直互相等待,直到发生崩溃。解决此问题的最干净的方法是创建一个特殊消息,服务器将发送给自己,以便在它返回(并且进程池监督者变为空闲)后能够在handle_info/2中处理它。
init({Limit, MFA, Sup}) ->
%% We need to find the Pid of the worker supervisor from here,
%% but alas, this would be calling the supervisor while it waits for us!
self() ! {start_worker_supervisor, Sup, MFA},
{ok, #state{limit=Limit, refs=gb_sets:empty()}}.
这个更简洁。然后我们可以转到handle_info/2函数,并添加以下子句。
handle_info({start_worker_supervisor, Sup, MFA}, S = #state{}) ->
{ok, Pid} = supervisor:start_child(Sup, ?SPEC(MFA)),
link(Pid),
{noreply, S#state{sup=Pid}};
handle_info(Msg, State) ->
io:format("Unknown msg: ~p~n", [Msg]),
{noreply, State}.
第一个子句是这里有趣的地方。我们找到发送给自己(必然是第一个接收到的)的消息,要求进程池监督者添加worker监督者,跟踪这个Pid,然后大功告成!我们的树现在完全初始化了。哇。您可以尝试编译所有内容,以确保到目前为止没有错误。不幸的是,我们仍然无法测试应用程序,因为还有太多东西缺失。
注意:如果您不喜欢在运行应用程序之前构建整个应用程序的想法,请不要担心。这样做是为了展示对整个事情的更清晰的推理。虽然我确实心中有总体设计(与我之前演示的一样),但我开始以一种小型的测试驱动方式编写这个进程池应用程序,在这里和那里进行一些测试,以及一系列重构,以使所有内容都处于可运行状态。
很少有Erlang程序员(就像大多数其他语言的程序员一样)能够在第一次尝试时就编写出可用于生产的代码,作者并不像例子中看起来那么聪明。
好的,我们已经解决了这个问题。现在我们将处理run/2函数。这是一个同步调用,其消息格式为{run, Args},工作方式如下。
handle_call({run, Args}, _From, S = #state{limit=N, sup=Sup, refs=R}) when N > 0 ->
{ok, Pid} = supervisor:start_child(Sup, Args),
Ref = erlang:monitor(process, Pid),
{reply, {ok,Pid}, S#state{limit=N-1, refs=gb_sets:add(Ref,R)}};
handle_call({run, _Args}, _From, S=#state{limit=N}) when N =< 0 ->
{reply, noalloc, S};
一个很长的函数头部,但我们可以看到大部分管理都在那里进行。只要进程池中有空闲位置(原始限制N由最初添加进程池的程序员决定),我们就接受启动worker。然后,我们设置一个监控器,以便知道它何时完成,将所有这些信息存储在我们的状态中,递减计数器,然后开始运行。
如果没有可用空间,我们只需回复noalloc。
对sync_queue/2的调用将给出非常相似的实现。
handle_call({sync, Args}, _From, S = #state{limit=N, sup=Sup, refs=R}) when N > 0 ->
{ok, Pid} = supervisor:start_child(Sup, Args),
Ref = erlang:monitor(process, Pid),
{reply, {ok,Pid}, S#state{limit=N-1, refs=gb_sets:add(Ref,R)}};
handle_call({sync, Args}, From, S = #state{queue=Q}) ->
{noreply, S#state{queue=queue:in({From, Args}, Q)}};
如果有空间容纳更多worker,那么第一个子句将与我们对run/2所做的事情完全相同。不同之处在于没有worker可以运行的情况。与上次回复noalloc不同,这一次它不回复调用者,而是保留From信息并将其排队,以便在有空间运行worker时再处理。我们很快就会看到如何将它们出队并处理它们,但现在,我们将使用以下子句完成handle_call/3回调。
handle_call(stop, _From, State) ->
{stop, normal, ok, State};
handle_call(_Msg, _From, State) ->
{noreply, State}.
这处理了未知情况和stop/1调用。现在我们可以专注于让async_queue/2工作。因为async_queue/2基本上不关心worker何时运行,并且根本不需要回复,所以决定将其设置为投递,而不是调用。您会发现它的逻辑与之前的两个选项非常相似。
handle_cast({async, Args}, S=#state{limit=N, sup=Sup, refs=R}) when N > 0 ->
{ok, Pid} = supervisor:start_child(Sup, Args),
Ref = erlang:monitor(process, Pid),
{noreply, S#state{limit=N-1, refs=gb_sets:add(Ref,R)}};
handle_cast({async, Args}, S=#state{limit=N, queue=Q}) when N =< 0 ->
{noreply, S#state{queue=queue:in(Args,Q)}};
%% Not going to explain this one!
handle_cast(_Msg, State) ->
{noreply, State}.
同样,除了不回复之外,唯一的重大区别在于,当没有空间容纳worker时,它会被排队。不过,这次我们没有From信息,只是将其发送到队列中而没有它;在这种情况下,限制不会改变。
我们什么时候知道是时候出队了呢?嗯,我们到处都设置了监控器,并将它们的引用存储在gb_sets中。每当worker停止时,我们都会收到通知。让我们从这里开始。
handle_info({'DOWN', Ref, process, _Pid, _}, S = #state{refs=Refs}) ->
io:format("received down msg~n"),
case gb_sets:is_element(Ref, Refs) of
true ->
handle_down_worker(Ref, S);
false -> %% Not our responsibility
{noreply, S}
end;
handle_info({start_worker_supervisor, Sup, MFA}, S = #state{}) ->
...
handle_info(Msg, State) ->
...
我们在这段代码中做的是确保收到的'DOWN'消息来自worker。如果它不是来自worker(这会让人惊讶),我们只是忽略它。但是,如果消息确实是我们想要的,我们会调用名为handle_down_worker/2的函数。
handle_down_worker(Ref, S = #state{limit=L, sup=Sup, refs=Refs}) ->
case queue:out(S#state.queue) of
{{value, {From, Args}}, Q} ->
{ok, Pid} = supervisor:start_child(Sup, Args),
NewRef = erlang:monitor(process, Pid),
NewRefs = gb_sets:insert(NewRef, gb_sets:delete(Ref,Refs)),
gen_server:reply(From, {ok, Pid}),
{noreply, S#state{refs=NewRefs, queue=Q}};
{{value, Args}, Q} ->
{ok, Pid} = supervisor:start_child(Sup, Args),
NewRef = erlang:monitor(process, Pid),
NewRefs = gb_sets:insert(NewRef, gb_sets:delete(Ref,Refs)),
{noreply, S#state{refs=NewRefs, queue=Q}};
{empty, _} ->
{noreply, S#state{limit=L+1, refs=gb_sets:delete(Ref,Refs)}}
end.
这是一个相当复杂的例子。因为我们的 worker 已经停止工作,我们可以查看队列中是否有下一个 worker 可以运行。我们通过从队列中弹出(pop)一个元素并查看结果来实现这一点。如果队列中至少有一个元素,它将是 `{{value, Item}, NewQueue}` 的形式。如果队列为空,它将返回 `{empty, SameQueue}`。此外,我们知道当我们拥有 `{{From, Args}}` 的值时,这意味着它来自 `sync_queue/2`,否则它来自 `async_queue/2`。
当队列中有任务时,两种情况的行为大致相同:一个新的 worker 将被附加到 worker supervisor,旧 worker 的 monitor 引用将被删除并替换为新 worker 的 monitor 引用。唯一的不同之处在于,在同步调用情况下,我们会发送一个手动回复,而在其他情况下,我们可以保持沉默。就是这样。
如果队列为空,我们只需要将 worker 限制增加一。
最后要做的是添加标准的 OTP 回调。
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
terminate(_Reason, _State) ->
ok.
就是这样,我们的池已经可以使用了!不过,它是一个很不友好的池。我们需要使用的所有函数都散落在各处。一些在 `ppool_supersup` 中,一些在 `ppool_serv` 中。而且模块名称没有理由那么长。为了使事情更友好,将以下 API 模块(只是抽象调用)添加到应用程序的目录中
%%% API module for the pool
-module(ppool).
-export([start_link/0, stop/0, start_pool/3,
run/2, sync_queue/2, async_queue/2, stop_pool/1]).
start_link() ->
ppool_supersup:start_link().
stop() ->
ppool_supersup:stop().
start_pool(Name, Limit, {M,F,A}) ->
ppool_supersup:start_pool(Name, Limit, {M,F,A}).
stop_pool(Name) ->
ppool_supersup:stop_pool(Name).
run(Name, Args) ->
ppool_serv:run(Name, Args).
async_queue(Name, Args) ->
ppool_serv:async_queue(Name, Args).
sync_queue(Name, Args) ->
ppool_serv:sync_queue(Name, Args).
现在我们真的完成了!
注意:你可能已经注意到我们的进程池没有限制可以存储在队列中的项数。在某些情况下,真正的服务器应用程序需要对可以排队的项数设置上限,以避免在使用过多内存时崩溃,尽管如果只使用 `run/2` 和 `sync_queue/2` 并且调用者的数量固定,则可以规避此问题(如果所有内容生产者都因等待池中的可用空间而阻塞,它们最初就不会产生那么多的内容)。
为队列大小添加限制留作练习,但不要担心,因为这相对容易做到;你需要向所有函数传递一个新的参数,这些函数一直传递到服务器,服务器会在进行任何排队之前检查限制。
此外,为了控制系统的负载,你可能希望通过使用同步调用在更靠近源头的地方设置限制。同步调用允许在系统被生产者比消费者更快地淹没时阻塞传入查询;这通常有助于使其比自由竞争的负载更有响应性。
编写一个 Worker
看看我,我一直都在撒谎!这个池实际上还没有准备好使用。我们目前还没有 worker。我忘了。这真是一件憾事,因为我们都知道在 关于编写并发应用程序的章节 中,我们已经写了一个很棒的任务提醒。这对我来说显然还不够,所以在这一章中,我会让我们编写一个提醒者。
它基本上将是每个任务的 worker,并且 worker 将通过发送重复消息直到达到某个截止日期来不断提醒我们。它将能够接收
- 一个用来提醒的时间延迟,
- 一个地址(pid)来指示消息应该发送到哪里
- 一个提醒消息,该消息将被发送到进程邮箱中,其中包括提醒者的 pid,以便能够调用...
- ...一个停止函数,用来指示任务已完成并且提醒者可以停止提醒
我们开始吧
%% demo module, a nagger for tasks,
%% because the previous one wasn't good enough
-module(ppool_nagger).
-behaviour(gen_server).
-export([start_link/4, stop/1]).
-export([init/1, handle_call/3, handle_cast/2,
handle_info/2, code_change/3, terminate/2]).
start_link(Task, Delay, Max, SendTo) ->
gen_server:start_link(?MODULE, {Task, Delay, Max, SendTo} , []).
stop(Pid) ->
gen_server:call(Pid, stop).
是的,我们将使用另一个 `gen_server`。你会发现人们总是使用它们,即使有时并不合适!重要的是要记住,我们的池可以接受任何符合 OTP 标准的进程,而不仅仅是 `gen_servers`。
init({Task, Delay, Max, SendTo}) ->
{ok, {Task, Delay, Max, SendTo}, Delay}.
这只是接收基本数据并转发它们。同样,`Task` 是要作为消息发送的东西,`Delay` 是每次发送之间的时间,`Max` 是要发送的次数,`SendTo` 是一个 pid 或一个名称,消息将被发送到那里。请注意,`Delay` 作为元组的第三个元素传递,这意味着 `timeout` 将在 `Delay` 毫秒后发送到 `handle_info/2`。
根据我们上面的 API,服务器的大部分内容都相当简单
%%% OTP Callbacks
handle_call(stop, _From, State) ->
{stop, normal, ok, State};
handle_call(_Msg, _From, State) ->
{noreply, State}.
handle_cast(_Msg, State) ->
{noreply, State}.
handle_info(timeout, {Task, Delay, Max, SendTo}) ->
SendTo ! {self(), Task},
if Max =:= infinity ->
{noreply, {Task, Delay, Max, SendTo}, Delay};
Max =< 1 ->
{stop, normal, {Task, Delay, 0, SendTo}};
Max > 1 ->
{noreply, {Task, Delay, Max-1, SendTo}, Delay}
end.
%% We cannot use handle_info below: if that ever happens,
%% we cancel the timeouts (Delay) and basically zombify
%% the entire process. It's better to crash in this case.
%% handle_info(_Msg, State) ->
%% {noreply, State}.
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
terminate(_Reason, _State) -> ok.
这里唯一有点复杂的部分是 `handle_info/2` 函数。正如我们在 `gen_server` 章节 中看到的那样,每次超时发生时(在本例中,在 `Delay` 毫秒之后),`timeout` 消息将被发送到进程。基于此,我们检查发送了多少次提醒,以确定我们是否需要发送更多提醒,或者是否应该退出。在这个 worker 完成后,我们实际上可以尝试使用这个进程池!
运行池
我们现在可以玩一下这个池,编译所有文件并启动池顶层 supervisor 本身
$ erlc *.erl
$ erl
Erlang R14B02 (erts-5.8.3) [source] [64-bit] [smp:4:4] [rq:4] [async-threads:0] [hipe] [kernel-poll:false]
Eshell V5.8.3 (abort with ^G)
1> ppool:start_link().
{ok,<0.33.0>}
从现在开始,我们可以尝试提醒者作为池的一系列不同功能
2> ppool:start_pool(nagger, 2, {ppool_nagger, start_link, []}).
{ok,<0.35.0>}
3> ppool:run(nagger, ["finish the chapter!", 10000, 10, self()]).
{ok,<0.39.0>}
4> ppool:run(nagger, ["Watch a good movie", 10000, 10, self()]).
{ok,<0.41.0>}
5> flush().
Shell got {<0.39.0>,"finish the chapter!"}
Shell got {<0.39.0>,"finish the chapter!"}
ok
6> ppool:run(nagger, ["clean up a bit", 10000, 10, self()]).
noalloc
7> flush().
Shell got {<0.41.0>,"Watch a good movie"}
Shell got {<0.39.0>,"finish the chapter!"}
Shell got {<0.41.0>,"Watch a good movie"}
Shell got {<0.39.0>,"finish the chapter!"}
Shell got {<0.41.0>,"Watch a good movie"}
...
对于同步的非排队运行,一切似乎都运行得很好。池启动了,任务被添加了,消息被发送到正确的目的地。当我们尝试运行的任务数超过允许的限制时,分配将被拒绝。现在没有时间清理,抱歉!不过其他任务仍然可以正常运行。
注意:`ppool` 使用 `start_link/0` 启动。如果你在 shell 中出现任何错误,整个池都会被关闭,你必须重新启动。这个问题将在下一章中解决。
注意:当然,一个更干净的提醒者可能会调用一个事件管理器,用来正确地将消息转发到所有适当的媒体。但在实践中,许多产品、协议和库都容易发生变化,我一直不喜欢那些一旦外部依赖关系过时就变得不再适宜阅读的书籍。因此,我倾向于将所有外部依赖关系保持在相当低的水平,如果不能完全没有的话。在本教程中,我尽量避免使用它们。
我们可以尝试一下排队功能(异步),看看
8> ppool:async_queue(nagger, ["Pay the bills", 30000, 1, self()]).
ok
9> ppool:async_queue(nagger, ["Take a shower", 30000, 1, self()]).
ok
10> ppool:async_queue(nagger, ["Plant a tree", 30000, 1, self()]).
ok
<wait a bit>
received down msg
received down msg
11> flush().
Shell got {<0.70.0>,"Pay the bills"}
Shell got {<0.72.0>,"Take a shower"}
<wait some more>
received down msg
12> flush().
Shell got {<0.74.0>,"Plant a tree"}
ok
太好了!所以排队功能可以正常工作。这里的日志没有以非常清晰的方式显示所有内容,但发生的事情是,前两个提醒者尽快运行。然后,worker 限制被达到,我们需要将第三个任务(种植树)排队。当支付账单的提醒完成时,种植树的提醒被调度,并在稍后发送消息。
同步的那个将表现不同
13> ppool:sync_queue(nagger, ["Pet a dog", 20000, 1, self()]).
{ok,<0.108.0>}
14> ppool:sync_queue(nagger, ["Make some noise", 20000, 1, self()]).
{ok,<0.110.0>}
15> ppool:sync_queue(nagger, ["Chase a tornado", 20000, 1, self()]).
received down msg
{ok,<0.112.0>}
received down msg
16> flush().
Shell got {<0.108.0>,"Pet a dog"}
Shell got {<0.110.0>,"Make some noise"}
ok
received down msg
17> flush().
Shell got {<0.112.0>,"Chase a tornado"}
ok
同样,日志不像你自己尝试时那么清晰(我鼓励你这样做)。事件的基本顺序是,两个 worker 被添加到池中。它们还没有完成运行,当我们尝试添加第三个 worker 时,shell 会被锁定,直到 `ppool_serv`(在进程名称 `nagger` 下)接收一个 worker 的 down 消息(`received down msg`)。在这之后,我们对 `sync_queue/2` 的调用可以返回并为我们提供新的 worker 的 pid。
我们现在可以去除整个池
18> ppool:stop_pool(nagger). ok 19> ppool:stop(). ** exception exit: killed
如果你决定只调用 `ppool:stop()`,所有池将被终止,但你会收到许多错误消息。这是因为我们粗暴地杀死了 `ppool_supersup` 进程,而不是正确地将其关闭(这反过来会使所有子池崩溃),但下一章将介绍如何干净地做到这一点。
清理池
回顾一下,我们已经成功地编写了一个进程池,以一种相对简单的方式进行一些资源分配。所有内容都可以并行处理,可以限制,也可以从其他进程调用。应用程序中崩溃的部分,借助于 supervisor,可以透明地替换,而不会破坏整个应用程序。一旦池应用程序准备就绪,我们甚至用很少的代码重写了我们提醒应用程序中相当大的一部分。
已经考虑到了单台计算机的故障隔离,并发性也得到了处理,我们现在拥有了足够的架构块来编写一些非常可靠的服务器端软件,尽管我们还没有真正看到从 shell 中运行它们的好方法...
下一章将介绍如何将 `ppool` 应用程序打包成一个真正的 OTP 应用程序,以便可以发布并供其他产品使用。到目前为止,我们还没有看到 OTP 的所有高级功能,但我可以告诉你,你现在已经达到了能够理解大多数关于 OTP 和 Erlang 的中级到初级高级讨论的水平(至少是不分布式的那部分)。这相当不错!