从头开始(真正开始)
Erlang 是一种相对较小且简单的语言(就像 C 比 C++ 更简单)。语言中内置了一些基本数据类型,因此本章将涵盖其中大多数。强烈建议您阅读它,因为它解释了您将使用 Erlang 编写的后面所有程序的基础。
数字
在 Erlang shell 中,**表达式必须以句点后跟空格(换行符、空格等)结束**,否则它们将不会被执行。您可以用逗号分隔表达式,但只会显示最后一个表达式的结果(其他表达式仍然会执行)。这对大多数人来说无疑是不同寻常的语法,它源于 Erlang 直接在 Prolog 中实现的时代,Prolog 是一种逻辑编程语言。
按照前几章的描述打开 Erlang shell,然后我们开始输入这些东西!
1> 2 + 15. 17 2> 49 * 100. 4900 3> 1892 - 1472. 420 4> 5 / 2. 2.5 5> 5 div 2. 2 6> 5 rem 2. 1
您应该已经注意到 Erlang 不关心您输入的是浮点数还是整数:在处理算术运算时,两种类型都受支持。  整数和浮点值几乎是 Erlang 的数学运算符为您透明处理的唯一类型的数据。但是,如果您希望进行整数除法,请使用
整数和浮点值几乎是 Erlang 的数学运算符为您透明处理的唯一类型的数据。但是,如果您希望进行整数除法,请使用 div,而对于取模运算,请使用 rem(余数)。
请注意,我们可以在单个表达式中使用多个运算符,并且数学运算遵循正常的优先级规则。
7> (50 * 100) - 4999. 1 8> -(50 * 100 - 4999). -1 9> -50 * (100 - 4999). 244950
如果您想用除十进制以外的其他进制表示整数,只需将数字输入为 Base#Value(前提是 Base 在 2..36 范围内)。
10> 2#101010. 42 11> 8#0677. 447 12> 16#AE. 174
太棒了!Erlang 拥有您桌面角落的计算器功能,并且在它的顶部拥有奇怪的语法!绝对令人兴奋!
不变变量
做算术运算还可以,但是如果您无法将结果存储在某处,您将不会走得太远。为此,我们将使用变量。如果您已经阅读了本书的简介,您就会知道在函数式编程中,变量不能是可变的。这些 7 个表达式可以演示变量的基本行为(请注意,变量以大写字母开头)。
1> One. * 1: variable 'One' is unbound 2> One = 1. 1 3> Un = Uno = One = 1. 1 4> Two = One + One. 2 5> Two = 2. 2 6> Two = Two + 1. ** exception error: no match of right hand side value 3 7> two = 2. ** exception error: no match of right hand side value 2
这些命令首先告诉我们,您只能为变量分配一次值;然后,如果您给变量分配的值与它已有的值相同,您可以“假装”为变量分配值。如果不同,Erlang 会报错。这是一个正确的观察结果,但解释稍微复杂一些,并且取决于 = 运算符。= 运算符(而不是变量)的作用是比较值,如果它们不同,则报错。如果它们相同,它将返回该值。
8> 47 = 45 + 2. 47 9> 47 = 45 + 3. ** exception error: no match of right hand side value 48
该运算符与变量混合使用时,它的行为是这样的:如果左侧项是未绑定的变量(没有与之关联的值),Erlang 将自动将右侧的值绑定到左侧的变量。比较将因此成功,变量将保留内存中的值。
= 运算符的这种行为是“模式匹配”的基础,许多函数式编程语言都有这种机制,尽管 Erlang 的实现方式通常被认为比其他方法更灵活和更完善。当我们访问本章中的元组和列表类型时,以及在接下来的章节中访问函数时,我们将更详细地了解模式匹配。
命令 1-7 还告诉我们,变量名必须以大写字母开头。命令 7 失败是因为单词 two 以小写字母开头。从技术上讲,变量也可以以下划线('_')开头,但按照惯例,它们的使用仅限于您不关心的值,但您觉得有必要记录它包含的内容。
您也可以拥有仅为下划线的变量。
10> _ = 14+3. 17 11> _. * 1: variable '_' is unbound
与任何其他类型的变量不同,它永远不会存储任何值。目前完全没有用,但是当我们需要它时,您就会知道它的存在。
**注意:**如果您在 shell 中进行测试并将错误的值保存到变量中,可以使用函数 f(Variable). “擦除”该变量。如果您想清除所有变量名,请执行 f().。
这些函数仅在您进行测试时才存在,并且仅在 shell 中工作。在编写真正的程序时,我们将无法以这种方式销毁值。如果承认 Erlang 可用于工业场景,那么它只在 shell 中才能做到这一点是有意义的:完全有可能让 shell 在没有任何中断的情况下运行多年……让我们打赌变量 X 在那段时间内会被使用不止一次。
原子
变量名不能以小写字母开头是有原因的:原子。原子是文字,它们的名称就是它们的值。您看到的就是您得到的,不要期待更多。原子 cat 表示“猫”,仅此而已。你不能玩弄它,你不能改变它,你不能把它砸成碎片;它是 cat。接受它。
虽然以小写字母开头的单个单词是编写原子的方法,但还有多种方法可以做到这一点。
1> atom. atom 2> atoms_rule. atoms_rule 3> atoms_rule@erlang. atoms_rule@erlang 4> 'Atoms can be cheated!'. 'Atoms can be cheated!' 5> atom = 'atom'. atom
如果原子不以小写字母开头或包含除字母数字字符、下划线(_)或 @ 以外的其他字符,则应将其用单引号 (') 括起来。
表达式 5 还表明,带单引号的原子与不带单引号的类似原子完全相同。
我将原子比作名称为值的常量。您可能使用过之前使用常量的代码:例如,假设我有眼睛颜色的值: 
BLUE -> 1, BROWN -> 2, GREEN -> 3, OTHER -> 4。您需要将常量的名称与一些底层值匹配。原子让您忘记底层值:我的眼睛颜色可以简单地是 'blue'、'brown'、'green' 和 'other'。这些颜色可以在任何代码片段中的任何位置使用:底层值永远不会冲突,并且这种常量不可能未定义!如果您真的想要与值相关的常量,您可以使用一种将在 第 4 章(模块)中看到的方法。
因此,原子主要用于表达或限定与其耦合的数据。单独使用它,很难找到一个好的用途。这就是我们不会花更多时间玩弄它们的原因;它们最好的用途是在与其他类型的数据耦合时出现。
不要喝太多酷乐饮料
原子非常棒,是发送消息或表示常量的绝佳方法。但是,将原子用于太多事物存在陷阱:原子在“原子表”中被引用,原子表会消耗内存(在 32 位系统中为 4 字节/原子,在 64 位系统中为 8 字节/原子)。原子表不会被垃圾回收,因此原子会不断累积,直到系统因内存使用或声明了 1048577 个原子而崩溃。
这意味着原子不应出于任何原因动态生成;如果您的系统必须可靠,并且用户输入允许某人通过告诉它创建原子来随意崩溃它,那么您就遇到了大麻烦。原子应该被视为开发人员的工具,因为老实说,它们就是工具。
**注意:**某些原子是保留字,除语言设计者希望它们成为的用途外,不能使用它们:函数名、运算符、表达式等。它们是:after and andalso band begin bnot bor bsl bsr bxor case catch cond div end fun if let not of or orelse query receive rem try when xor

布尔代数和比较运算符
如果无法区分大小、真假,那就麻烦大了。与其他语言一样,Erlang 也提供了一些方法让您使用布尔运算并比较项目。
布尔代数非常简单
1> true and false. false 2> false or true. true 3> true xor false. true 4> not false. true 5> not (true and true). false
**注意:**布尔运算符 and 和 or 将始终计算运算符两侧的参数。如果您想要使用短路运算符(仅在需要时才计算右侧参数),请使用 andalso 和 orelse。
测试相等或不相等也很简单,但与您在许多其他语言中看到的符号略有不同。
6> 5 =:= 5. true 7> 1 =:= 0. false 8> 1 =/= 0. true 9> 5 =:= 5.0. false 10> 5 == 5.0. true 11> 5 /= 5.0. false
首先,如果您的常用语言使用 == 和 != 来测试相等和不相等,Erlang 使用 =:= 和 =/=。最后三个表达式(第 9 行到第 11 行)也为我们介绍了一个陷阱:Erlang 不会在意算术运算中的浮点数和整数,但在比较它们时会这样做。不过不用担心,因为 == 和 /= 运算符可以帮助您处理这些情况。在您是否需要精确的相等性时,这一点很重要。
其他比较运算符有 <(小于)、>(大于)、>=(大于或等于)和 =<(小于或等于)。最后一个比较运算符(在我看来)是反过来的,并且是我代码中许多语法错误的根源。注意 =<。
12> 1 < 2. true 13> 1 < 1. false 14> 1 >= 1. true 15> 1 =< 1. true
执行 5 + llama 或 5 == true 会发生什么?没有比尝试一下,然后被错误消息吓到更好的方法了!
12> 5 + llama.
** exception error: bad argument in an arithmetic expression
in operator +/2
called as 5 + llama
好吧!Erlang 确实不喜欢您错误地使用一些基本类型!模拟器在这里返回一个漂亮的错误消息。它告诉我们它不喜欢 + 运算符两侧使用的两个参数中的一个!
Erlang 由于类型错误而生气并非总是真的。
13> 5 =:= true. false
为什么它拒绝在某些操作中使用不同类型,而在其他操作中不拒绝?虽然 Erlang 不允许您用任何东西添加任何东西,但它允许您比较它们。这是因为 Erlang 的创建者认为实用主义胜过理论,并决定能够简单地编写诸如能够对任何项进行排序的通用排序算法将是件好事。它的存在是为了让您的生活更轻松,并且在大多数情况下都可以做到这一点。
在进行布尔代数和比较时,还有一点需要注意。
14> 0 == false. false 15> 1 < false. true
如果您来自过程式语言或大多数面向对象的语言,您可能会扯头发。第 14 行应该评估为 true,第 15 行应该评估为 false!毕竟,false 表示 0,true 表示任何其他值!除了在 Erlang 中。因为我骗了你。是的,我做了。真不应该。
Erlang 没有像布尔值 true 和 false 这样的东西。true 和 false 是原子,但它们与语言很好地集成,只要你不期望 false 和 true 意味着除了 false 和 true 之外的任何东西,你就不应该遇到任何问题。
注意: 比较中每个元素的正确排序如下
数字 < 原子 < 引用 < 函数 < 端口 < 进程 < 元组 < 列表 < 位字符串
你可能还不知道所有这些类型,但你将通过本书了解它们。请记住,这就是为什么你可以用任何东西比较任何东西!引用 Erlang 的创始人之一 Joe Armstrong 的话说:“实际顺序并不重要,重要的是总排序是明确定义的。”
元组
元组是一种组织数据的方式。当你知道有多少项时,它是一种将多个项组合在一起的方式。在 Erlang 中,元组以 {Element1, Element2, ..., ElementN} 的形式编写。例如,如果你想告诉我笛卡尔坐标系中一个点的坐标 (x,y),你就会给我这个坐标。我们可以将这个点表示为一个包含两个项的元组
1> X = 10, Y = 4.
4
2> Point = {X,Y}.
{10,4}
在这种情况下,一个点总是包含两个项。你只需要携带一个,而不是四处携带 X 和 Y 变量。但是,如果我收到一个点,只想得到 X 坐标,我该怎么办?提取该信息并不难。请记住,当我们赋值时,Erlang 永远不会抱怨它们是否相同。让我们利用这一点!你可能需要清理我们用 f() 设置的变量。
3> Point = {4,5}.
{4,5}
4> {X,Y} = Point.
{4,5}
5> X.
4
6> {X,_} = Point.
{4,5}
从那时起,我们可以使用 X 来获取元组的第一个值!这是怎么发生的?  首先,X 和 Y 没有值,因此被认为是未绑定的变量。当我们在
首先,X 和 Y 没有值,因此被认为是未绑定的变量。当我们在 = 运算符的左侧将它们设置为元组 {X,Y} 时,= 运算符会比较两个值:{X,Y} 与 {4,5}。Erlang 足够智能,可以从元组中解包值并将其分配给左侧的未绑定变量。然后比较只是 {4,5} = {4,5},这显然成功了!这是模式匹配的多种形式之一。
请注意,在表达式 6 中,我使用了匿名变量 _。这正是它应该使用的:丢弃通常放在那里的值,因为我们不会使用它。变量 _ 始终被视为未绑定的,并且充当模式匹配的通配符。解包元组的模式匹配只有在元素数量(元组的长度)相同的情况下才会起作用。
7> {_,_} = {4,5}.
{4,5}
8> {_,_} = {4,5,6}.
** exception error: no match of right hand side value {4,5,6}
当处理单个值时,元组也很有用。怎样?最简单的例子是温度
9> Temperature = 23.213. 23.213
好吧,听起来去海滩是不错的选择……等等,这个温度是开尔文、摄氏还是华氏度?
10> PreciseTemperature = {celsius, 23.213}.
{celsius,23.213}
11> {kelvin, T} = PreciseTemperature.
** exception error: no match of right hand side value {celsius,23.213}
这会引发错误,但这正是我们想要的!这又是模式匹配在起作用。= 运算符最终会比较 {kelvin, T} 和 {celsius, 23.213}:即使变量 T 未绑定,Erlang 在比较时也不会将原子 celsius 视为与原子 kelvin 相同。会抛出一个异常,停止代码执行。这样一来,我们程序中期望开尔文温度的那部分将无法处理以摄氏度发送的温度。这使得程序员更容易知道正在发送的内容,并且还可以作为调试辅助工具。包含一个原子和一个跟随它的元素的元组被称为“带标签的元组”。元组的任何元素都可以是任何类型,甚至可以是另一个元组
12> {point, {X,Y}}.
{point,{4,5}}
如果我们想携带多个 Point 呢?
列表!
列表是许多函数式编程语言的“面包和黄油”。它们用于解决各种问题,并且无疑是 Erlang 中使用最多的数据结构。列表可以包含任何东西!数字、原子、元组、其他列表;你最疯狂的梦想,全部在一个结构中。列表的基本表示法是 [Element1, Element2, ..., ElementN],你可以在其中混合多种数据类型
1> [1, 2, 3, {numbers,[4,5,6]}, 5.34, atom].
[1,2,3,{numbers,[4,5,6]},5.34,atom]
很简单,对吧?
2> [97, 98, 99]. "abc"
哦!这是 Erlang 中最不受欢迎的事情之一:字符串!字符串是列表,表示法完全相同!为什么人们不喜欢它?因为这样
3> [97,98,99,4,5,6]. [97,98,99,4,5,6] 4> [233]. "é"
只有当至少其中一个数字不能表示字母时,Erlang 才会将数字列表打印为数字!在 Erlang 中,没有真正的字符串!这无疑会在将来困扰你,你会因此讨厌这种语言。别绝望,因为本章后面我们会看到其他编写字符串的方法。
不要喝太多酷乐饮料
这就是你可能听说 Erlang 在字符串操作方面很糟糕的原因:它不像大多数其他语言那样具有内置的字符串类型。这是因为 Erlang 最初是电信公司创建和使用的语言。他们从未(或很少)使用字符串,因此从未想过正式添加它们。但是,随着时间的推移,Erlang 在字符串操作方面的大部分缺乏逻辑正在得到解决:VM 现在原生支持 Unicode 字符串,并且总体上在字符串操作方面越来越快。
还有一种方法可以将字符串存储为二进制数据结构,使它们非常轻便,并且可以更快地处理。总而言之,标准库中仍然缺少一些函数,虽然字符串处理在 Erlang 中是可以实现的,但对于需要大量字符串处理的任务(如 Perl 或 Python)来说,有一些更好的语言。
为了将列表粘合在一起,我们使用 ++ 运算符。++ 的相反是 --,它将从列表中删除元素
5> [1,2,3] ++ [4,5]. [1,2,3,4,5] 6> [1,2,3,4,5] -- [1,2,3]. [4,5] 7> [2,4,2] -- [2,4]. [2] 8> [2,4,2] -- [2,4,2]. []
++ 和 -- 都是右结合的。这意味着许多 -- 或 ++ 操作的元素将从右到左执行,如下例所示
9> [1,2,3] -- [1,2] -- [3]. [3] 10> [1,2,3] -- [1,2] -- [2]. [2,3]
让我们继续。列表的第一个元素称为头部,列表的其余部分称为尾部。我们将使用两个内置函数 (BIF) 来获取它们。
11> hd([1,2,3,4]). 1 12> tl([1,2,3,4]). [2,3,4]
注意: 内置函数 (BIF) 通常是无法用纯 Erlang 实现的函数,因此在 C 或 Erlang 所实现的任何语言中定义(在 80 年代是 Prolog)。仍然有一些 BIF 可以用 Erlang 完成,但仍然在 C 中实现,以提供更快的通用操作速度。其中一个例子是 length(List) 函数,它将返回(你猜对了)作为参数传入的列表的长度。
访问或添加头部是快速有效的:几乎所有需要处理列表的应用程序都将始终首先操作头部。由于它非常频繁地使用,因此有一种更简洁的方法可以借助模式匹配将头部与列表的尾部分开:[Head|Tail]。以下是添加新头部到列表的方法
13> List = [2,3,4]. [2,3,4] 14> NewList = [1|List]. [1,2,3,4]
在处理列表时,由于你通常从头部开始,因此你希望有一种快速的方法来存储尾部以便稍后对其进行操作。如果你还记得元组的工作方式以及我们如何使用模式匹配来解包点的值 ({X,Y}),你就会知道我们可以以类似的方式从列表中切除第一个元素(头部)。
15> [Head|Tail] = NewList. [1,2,3,4] 16> Head. 1 17> Tail. [2,3,4] 18> [NewHead|NewTail] = Tail. [2,3,4] 19> NewHead. 2
我们使用的 | 被称为 cons 运算符(构造函数)。事实上,任何列表都可以仅用 cons 和值构建
20> [1 | []]. [1] 21> [2 | [1 | []]]. [2,1] 22> [3 | [2 | [1 | []] ] ]. [3,2,1]
也就是说,任何列表都可以使用以下公式构建:[Term1| [Term2 | [... | [TermN]]]]...。因此,列表可以递归地定义为头部在尾部之前,尾部本身是一个头部,后面是更多头部。从这个意义上说,我们可以想象一个列表有点像蚯蚓:你可以把它切成两半,然后就会有两条虫子。

Erlang 列表的构建方式有时会让不习惯类似构造函数的人感到困惑。为了帮助你熟悉这个概念,请阅读所有这些示例(提示:它们都是等效的)
[a, b, c, d] [a, b, c, d | []] [a, b | [c, d]] [a, b | [c | [d]]] [a | [b | [c | [d]]]] [a | [b | [c | [d | [] ]]]]
有了这些理解,你应该能够处理列表推导。
注意: 使用 [1 | 2] 的形式会得到我们所谓的“不完整列表”。不完整列表在以 [Head|Tail] 的方式进行模式匹配时会起作用,但无法与 Erlang 的标准函数一起使用(即使是 length())。这是因为 Erlang 期望完整列表。完整列表以空列表作为最后一个单元格结束。当声明像 [2] 这样的项时,列表会自动以完整的方式形成。因此,[1|[2]] 会起作用!不完整列表虽然在语法上有效,但在用户定义的数据结构之外的用途非常有限。
列表推导
列表推导是构建或修改列表的方式。与其他处理列表的方式相比,它们还可以使程序更短、更容易理解。它基于集合表示法的概念;如果你曾经参加过包含集合论的数学课程,或者如果你曾经看过数学符号,你可能知道它是如何工作的。集合表示法基本上告诉你要如何通过指定其成员必须满足的属性来构建一个集合。列表推导可能刚开始很难理解,但它们值得付出努力。它们使代码更简洁、更短,所以不要犹豫,尝试输入示例,直到你理解它们为止!
集合表示法的示例是 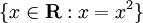 。该集合表示法告诉你,你想要的结果将是所有等于自身平方的实数。该集合的结果将是 {0,1}。另一个更简单、更简化的集合表示法示例是
。该集合表示法告诉你,你想要的结果将是所有等于自身平方的实数。该集合的结果将是 {0,1}。另一个更简单、更简化的集合表示法示例是 {x : x > 0}。在这里,我们想要的是所有 x > 0 的数字。
Erlang 中的列表推导是关于从其他集合中构建集合。假设集合 {2n : n in L},其中 L 是列表 [1,2,3,4],Erlang 实现将是
1> [2*N || N <- [1,2,3,4]]. [2,4,6,8]
比较数学符号和 Erlang 符号,没有太多变化:大括号 ({}) 变成了方括号 ([]), 冒号 (:) 变成了两个竖线 (||),而“in”一词变成了箭头 (<-)。我们只更改符号,并保持相同的逻辑。在上面的示例中,[1,2,3,4] 的每个值都按顺序与 N 进行模式匹配。箭头就像 = 运算符一样,只是它不会抛出异常。
你也可以通过使用返回布尔值的运算来向列表推导添加约束。如果我们想要从一到十的所有偶数,我们可以编写类似下面的内容
2> [X || X <- [1,2,3,4,5,6,7,8,9,10], X rem 2 =:= 0]. [2,4,6,8,10]
其中 X rem 2 =:= 0 检查一个数字是否为偶数。当我们决定要将函数应用于列表的每个元素时,会产生实际应用,迫使它遵守约束条件等等。例如,假设我们拥有一个餐厅。顾客进来,看到我们的菜单,并询问是否可以获得所有价格在 3 美元到 10 美元之间的商品的价格(加上 7% 的税)。
3> RestaurantMenu = [{steak, 5.99}, {beer, 3.99}, {poutine, 3.50}, {kitten, 20.99}, {water, 0.00}].
[{steak,5.99},
{beer,3.99},
{poutine,3.5},
{kitten,20.99},
{water,0.0}]
4> [{Item, Price*1.07} || {Item, Price} <- RestaurantMenu, Price >= 3, Price =< 10].
[{steak,6.409300000000001},{beer,4.2693},{poutine,3.745}]
当然,小数点没有以可读的方式进行四舍五入,但你明白我的意思。因此,Erlang 中列表推导的配方是 NewList = [Expression || Pattern <- List, Condition1, Condition2, ... ConditionN]。Pattern <- List 部分称为生成器表达式。你可以有多个生成器表达式!
5> [X+Y || X <- [1,2], Y <- [2,3]]. [3,4,4,5]
这运行操作1+2、1+3、2+2、2+3。因此,如果你想使列表推导公式更加通用,你将得到:NewList = [Expression || GeneratorExp1, GeneratorExp2, ..., GeneratorExpN, Condition1, Condition2, ... ConditionM]。请注意,与模式匹配相结合的生成器表达式也充当过滤器。
6> Weather = [{toronto, rain}, {montreal, storms}, {london, fog},
6> {paris, sun}, {boston, fog}, {vancouver, snow}].
[{toronto,rain},
{montreal,storms},
{london,fog},
{paris,sun},
{boston,fog},
{vancouver,snow}]
7> FoggyPlaces = [X || {X, fog} <- Weather].
[london,boston]
如果列表 'Weather' 中的元素与模式 {X, fog} 不匹配,它在列表推导中将被简单地忽略,而=运算符将抛出异常。
现在,我们还剩下一个基本数据类型需要学习。它是一个令人惊讶的功能,可以使解释二进制数据变得轻而易举。
位语法!
大多数语言都支持操作数据,例如数字、原子、元组、列表、记录和/或结构体等等。它们中的大多数也只提供了非常原始的功能来操作二进制数据。Erlang 竭尽全力在处理二进制值时提供有用的抽象,并将模式匹配提升到一个新的高度。它使处理原始二进制数据变得有趣且容易(是的,真的),这是为了帮助它创建的电信应用程序而必需的。位操作具有独特的语法和习惯用法,乍一看可能有点奇怪,但如果你了解位和字节的通用工作原理,这应该是有意义的。否则,你可能想跳过本章的其余部分。
位语法将二进制数据括在<<和>>之间,将其分成可读的段,每个段之间用逗号隔开。一个段是一个二进制位的序列(不一定在字节边界上,尽管这是默认行为)。假设我们想要存储一个真彩色(24 位)的橙色像素。如果你曾经在 Photoshop 或 Web 的 CSS 样式表中检查过颜色,你会知道十六进制表示法具有格式 #RRGGBB。橙色的色调在该表示法中为#F09A29,它可以在 Erlang 中扩展为
1> Color = 16#F09A29. 15768105 2> Pixel = <<Color:24>>. <<240,154,41>>
这基本上表示“将#F09A29的二进制值放在变量 Pixel 的 24 位空间中(红色在 8 位,绿色在 8 位,蓝色也在 8 位)”。该值随后可以被写入文件。这看起来并不多,但是一旦写入文件,你在文本编辑器中打开它时,你将得到一堆不可读的字符。当你从文件中读回时,Erlang 将再次将二进制数据解释为友好的<<240,151,41>>格式!
更有趣的是能够用二进制数据进行模式匹配以解包内容。
3> Pixels = <<213,45,132,64,76,32,76,0,0,234,32,15>>.
<<213,45,132,64,76,32,76,0,0,234,32,15>>
4> <<Pix1,Pix2,Pix3,Pix4>> = Pixels.
** exception error: no match of right hand side value <<213,45,132,64,76,32,76,
0,0,234,32,15>>
5> <<Pix1:24, Pix2:24, Pix3:24, Pix4:24>> = Pixels.
<<213,45,132,64,76,32,76,0,0,234,32,15>>
我们在命令 3 上所做的是声明将是精确的 4 个 RGB 颜色像素的二进制数据。
在表达式 4 上,我们试图从二进制内容中解包 4 个值。它抛出一个异常,因为我们有超过 4 个段,实际上我们有 12 个!因此,我们所做的是告诉 Erlang 左右两边的每个变量将保存 24 位的数据。这就是Var:24的含义。然后,我们可以取第一个像素,并将其进一步解包为单个颜色值
6> <<R:8, G:8, B:8>> = <<Pix1:24>>. <<213,45,132>> 7> R. 213
“是的,这很好。如果我只想从一开始就获取第一个颜色呢?我是否必须始终解包所有这些值?”哈哈!不要怀疑!Erlang 引入了更多的语法糖和模式匹配来帮助你解决问题。
8> <<R:8, Rest/binary>> = Pixels. <<213,45,132,64,76,32,76,0,0,234,32,15>> 9> R. 213
不错,对吧?这是因为 Erlang 接受多种方式来描述二进制段。这些都是有效的
Value Value:Size Value/TypeSpecifierList Value:Size/TypeSpecifierList
其中Size将表示位或字节(取决于下面的Type和Unit),而TypeSpecifierList表示以下的一种或多种
- 类型
- 可能的值:
integer | float | binary | bytes | bitstring | bits | utf8 | utf16 | utf32 - 这表示所使用的二进制数据类型。请注意,'bytes' 是 'binary' 的简写,而 'bits' 是 'bitstring' 的简写。如果没有指定类型,Erlang 假设为 'integer' 类型。
- 符号
- 可能的值:
signed | unsigned - 仅在类型为整数时匹配时才重要。默认值为 'unsigned'。
- 字节序
- 可能的值:
big | little | native - 字节序仅在类型为整数、utf16、utf32 或浮点数时才重要。这与系统如何读取二进制数据有关。例如,BMP 图像头格式将其文件大小存储为 4 字节上的整数。对于大小为 72 字节的文件,小端系统会将其表示为
<<72,0,0,0>>,而大端系统会将其表示为<<0,0,0,72>>。一个将被读为 '72',而另一个将被读为 '1207959552',因此请确保使用正确的字节序。还可以选择使用 'native',它将在运行时选择 CPU 本地使用小端字节序还是大端字节序。默认情况下,字节序设置为 'big'。 - 单元
- 写为
unit:Integer - 这是每个段的大小,以位为单位。允许的范围是 1..256,默认情况下对于整数、浮点数和位字符串设置为 1,对于二进制设置为 8。utf8、utf16 和 utf32 类型不需要定义单元。Size 与 Unit 的乘积等于段所占的位数,必须能被 8 整除。单元大小通常用于确保字节对齐。
TypeSpecifierList 通过用 '-' 分隔属性来构建。
一些示例可能有助于理解这些定义
10> <<X1/unsigned>> = <<-44>>. <<"Ô">> 11> X1. 212 12> <<X2/signed>> = <<-44>>. <<"Ô">> 13> X2. -44 14> <<X2/integer-signed-little>> = <<-44>>. <<"Ô">> 15> X2. -44 16> <<N:8/unit:1>> = <<72>>. <<"H">> 17> N. 72 18> <<N/integer>> = <<72>>. <<"H">> 19> <<Y:4/little-unit:8>> = <<72,0,0,0>>. <<72,0,0,0>> 20> Y. 72
你可以看到有不止一种方法来读取、存储和解释二进制数据。这有点令人困惑,但仍然比使用大多数语言提供的常用工具简单得多。
标准二进制操作(将位左移和右移、二进制 'and'、'or'、'xor' 或 'not')也在 Erlang 中存在。只需使用函数bsl(位左移)、bsr(位右移)、band、bor、bxor 和bnot。
2#00100 = 2#00010 bsl 1. 2#00001 = 2#00010 bsr 1. 2#10101 = 2#10001 bor 2#00101.
使用这种表示法和位语法,解析和模式匹配二进制数据就小菜一碟。人们可以用这样的代码解析 TCP 段
<<SourcePort:16, DestinationPort:16, AckNumber:32, DataOffset:4, _Reserved:4, Flags:8, WindowSize:16, CheckSum: 16, UrgentPointer:16, Payload/binary>> = SomeBinary.
然后可以将相同的逻辑应用于任何二进制数据:视频编码、图像、其他协议实现等等。
不要喝太多酷乐饮料
与 C 或 C++ 等语言相比,Erlang 速度较慢。除非你是一个有耐心的人,否则用它来做视频或图像转换之类的事情可能不是一个好主意,尽管如上所述,二进制语法使它变得非常有趣。Erlang 在进行繁重的数字运算方面并不擅长。
但是请注意,对于不需要数字运算的应用程序,Erlang 仍然非常快:对事件做出反应,消息传递(在原子的帮助下,原子非常轻量级)等等。它可以在几毫秒内处理事件,因此是软实时应用程序的理想选择。
二进制表示法还有另一个方面:位字符串。位字符串像列表一样附加在语言之上,但它们在空间效率方面更高。这是因为普通列表是链表(每个字母 1 个 '节点'),而位字符串更像 C 数组。位字符串使用语法<<"this is a bit string!">>。与列表相比,位字符串的缺点是,在模式匹配和操作方面,它在简单性方面有所损失。因此,人们倾向于在存储不会被过多操作的文本或空间效率是一个真正问题时使用位字符串。
注意:即使位字符串非常轻量级,也应该避免使用它们来标记值。使用字符串字面量来表示{<<"temperature">>,50}可能很诱人,但始终在这样做时使用原子。本章之前已经提到,原子只占用 4 或 8 字节的空间,无论它们有多长。通过使用它们,在将数据从一个函数复制到另一个函数或将其发送到另一个服务器上的另一个 Erlang 节点时,你基本上不会有任何开销。
相反,不要使用原子来替换字符串,因为它们更轻量级。字符串可以被操作(分割、正则表达式等等),而原子只能被比较,而不能做其他任何事情。
二进制推导
二进制推导对于位语法来说就像列表推导对于列表一样:一种使代码简短简洁的方法。它们在 Erlang 世界中是比较新的,因为它们存在于 Erlang 的先前版本中,但是需要一个实现它们的模块来使用一个特殊的编译标志才能正常工作。从 R13B 版本(此处使用的版本)开始,它们已成为标准,可以在任何地方使用,包括 shell
1> [ X || <<X>> <= <<1,2,3,4,5>>, X rem 2 == 0]. [2,4]
与普通列表推导唯一的语法区别是<-变成了<=,并且使用二进制数据(<<>>)而不是列表([])。本章前面我们已经看到了一个示例,其中有一个包含许多像素的二进制值,我们在该值上使用了模式匹配来获取每个像素的 RGB 值。这还可以,但在更大的结构上,它可能会变得更难阅读和维护。可以使用单行二进制推导来完成相同的练习,这要干净得多
2> Pixels = <<213,45,132,64,76,32,76,0,0,234,32,15>>.
<<213,45,132,64,76,32,76,0,0,234,32,15>>
3> RGB = [ {R,G,B} || <<R:8,G:8,B:8>> <= Pixels ].
[{213,45,132},{64,76,32},{76,0,0},{234,32,15}]
将<-更改为<=使我们可以使用二进制流作为生成器。完整的二进制推导基本上将二进制数据更改为元组中的整数。另一种二进制推导语法存在,让你可以执行完全相反的操作
4> << <<R:8, G:8, B:8>> || {R,G,B} <- RGB >>.
<<213,45,132,64,76,32,76,0,0,234,32,15>>
小心,因为如果生成器返回二进制数据,则结果二进制数据的元素需要明确定义的大小
5> << <<Bin>> || Bin <- [<<3,7,5,4,7>>] >>. ** exception error: bad argument 6> << <<Bin/binary>> || Bin <- [<<3,7,5,4,7>>] >>. <<3,7,5,4,7>>
如果在上面提到的固定大小规则得到遵守的情况下,也可以使用二进制生成器进行二进制推导
7> << <<(X+1)/integer>> || <<X>> <= <<3,7,5,4,7>> >>. <<4,8,6,5,8>>
注意:在撰写本文时,二进制推导很少使用,而且没有得到很好的文档记录。因此,决定不深入探究比识别它们并理解它们的正常工作原理所必需的更多内容。要更全面地了解位语法,请阅读定义其规范的白皮书.