应用程序计数
从 OTP 应用程序到真实应用程序
我们的 ppool 应用程序已成为一个有效的 OTP 应用程序,我们现在能够理解这意味着什么。不过,如果能构建一个真正利用我们的进程池来完成一些有用工作的东西,那就太好了。为了进一步提升我们对应用程序的了解,我们将编写第二个应用程序。这个应用程序将依赖于 ppool,但将能够从比我们的“唠叨者”更多的自动化中获益。
这个我将命名为 erlcount 的应用程序,将有一个相当简单的目标:递归地查看某个目录,找到所有 Erlang 文件(以 .erl 结尾),然后对其运行正则表达式以统计模块中给定字符串的所有实例。然后累积结果以给出最终结果,该结果将输出到屏幕上。
这个特定的应用程序将相对简单,将主要依赖于我们的进程池。它将具有以下结构
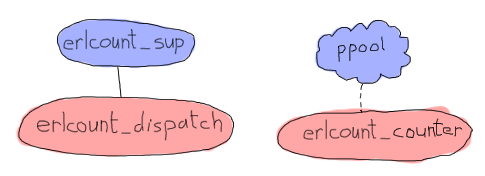
在上图中,ppool 代表整个应用程序,但只表示 erlcount_counter 将是进程池的工作进程。它将打开文件,运行正则表达式并返回计数。进程/模块 erlcount_sup 将是我们的主管,而 erlcount_dispatch 将是一个负责浏览目录、要求 ppool 调度工作进程并编译结果的单一服务器。我们还将添加一个 erlcount_lib 模块,负责托管所有读取目录、编译数据等等的函数,让其他模块负责协调这些调用。最后将是一个 erlcount 模块,它唯一的目的是作为应用程序回调模块。
第一步,就像我们上一个应用程序一样,是创建需要的目录结构。如果你想,也可以添加一些文件存根
ebin/ - erlcount.app include/ priv/ src/ - erlcount.erl - erlcount_counter.erl - erlcount_dispatch.erl - erlcount_lib.erl - erlcount_sup.erl test/ Emakefile
与之前没什么不同,你甚至可以复制之前使用的 Emakefile。
我们可能可以很快开始编写应用程序的大部分内容。.app 文件、计数器、库和主管应该相对简单。另一方面,如果我们希望事情变得更有意义,调度程序模块将不得不完成一些复杂的任务。让我们从 应用程序文件 开始
{application, erlcount,
[{vsn, "1.0.0"},
{modules, [erlcount, erlcount_sup, erlcount_lib,
erlcount_dispatch, erlcount_counter]},
{applications, [ppool]},
{registered, [erlcount]},
{mod, {erlcount, []}},
{env,
[{directory, "."},
{regex, ["if\\s.+->", "case\\s.+\\sof"]},
{max_files, 10}]}
]}.
这个应用程序文件比 ppool 文件更复杂。我们仍然可以识别一些字段是相同的:这个应用程序的版本也将是 1.0.0,列出的模块与上面相同。下一部分是我们之前没有的:应用程序依赖项。如前所述,applications 元组给出了在 erlcount 之前应该启动的所有应用程序的列表。如果你尝试在没有它的情况下启动它,你会收到错误消息。然后,我们必须使用 {registered, [erlcount]} 来统计注册的进程。从技术上讲,我们作为 erlcount 应用程序的一部分启动的模块都不需要名称。我们所做的一切都可以是匿名的。但是,因为我们知道 ppool 会将 ppool_serv 注册到我们给它的名称,并且因为我们知道我们将使用进程池,所以我们将把它命名为 erlcount 并在那里记录它。如果所有使用 ppool 的应用程序都这样做,我们应该能够在将来检测到冲突。mod 元组与之前类似;我们在那里定义应用程序行为回调模块。

这里最后一个新东西是 env 元组。如前所述,这个整个元组为我们提供了应用程序特定配置变量的键值存储。这些变量将从在应用程序中运行的所有进程中访问,并存储在内存中,以方便你使用。它们基本上可以被用作你应用程序的替代配置文件。
在这种情况下,我们定义了三个变量:directory,它告诉应用程序在哪里查找 .erl 文件(假设我们从 erlcount-1.0 目录运行应用程序,这意味着 learn-you-some-erlang 根目录),然后我们有 max_files 告诉我们应该同时打开多少个文件描述符。我们不希望在遇到这么多文件时同时打开 10,000 个文件,因此这个变量将与 ppool 中的最大工作进程数量匹配。然后,最复杂的变量是 regex。它将包含我们要对每个文件运行的所有正则表达式,以统计结果。
我不会详细解释 Perl 兼容正则表达式 的语法(如果你有兴趣,re 模块包含一些文档),但仍将解释我们在做什么。在本例中,第一个正则表达式表示“查找包含 'if' 后跟任何单个空格字符(\s,使用第二个反斜杠进行转义)并在 -> 结尾的字符串。此外,在 'if' 和 ->(.+)之间可以有任何内容”。第二个正则表达式表示“查找包含 'case' 后跟任何单个空格字符(\s),并在前面有单个空格字符的 'of' 结尾的字符串。在 'case ' 和 ' of' 之间,可以有任何内容(.+)”。为了简单起见,我们将尝试统计我们在库中使用 case ... of 的次数与使用 if ... end 的次数。
不要喝太多酷乐时
使用正则表达式来分析 Erlang 代码并不是最佳选择。问题是,有很多情况会导致我们的结果不准确,包括文本和注释中的字符串,它们与我们正在寻找的模式匹配,但在技术上不是代码。
为了获得更准确的结果,我们需要直接在 Erlang 中查看模块的解析版本和扩展版本。虽然更复杂(超出了本文的范围),但这将确保我们处理所有内容,例如宏,排除注释,并以正确的方式进行。
在这个文件完成之后,我们可以开始 应用程序回调模块。它不会很复杂,基本上只启动主管
-module(erlcount).
-behaviour(application).
-export([start/2, stop/1]).
start(normal, _Args) ->
erlcount_sup:start_link().
stop(_State) ->
ok.
现在是 主管本身
-module(erlcount_sup).
-behaviour(supervisor).
-export([start_link/0, init/1]).
start_link() ->
supervisor:start_link(?MODULE, []).
init([]) ->
MaxRestart = 5,
MaxTime = 100,
{ok, {{one_for_one, MaxRestart, MaxTime},
[{dispatch,
{erlcount_dispatch, start_link, []},
transient,
60000,
worker,
[erlcount_dispatch]}]}}.
这是一个标准主管,它将只负责 erlcount_dispatch,就像之前的小模式中所示。MaxRestart、MaxTime 和关闭的 60 秒值是随机选择的,但在实际情况下,你可能需要研究你的需求。因为这是一个演示应用程序,所以当时看起来并不重要。作者保留自己的懒惰权利。
我们可以进入链中的下一个进程和模块,调度程序。调度程序将需要满足一些复杂的要求才能发挥作用
- 当我们遍历目录以查找以
.erl结尾的文件时,即使我们应用多个正则表达式,我们也应该只遍历整个目录列表一次; - 我们应该能够在我们发现符合我们标准的文件时立即开始调度文件进行结果计数。我们不需要等待完整的列表来执行此操作。
- 我们需要为每个正则表达式保留一个计数器,以便我们最终能够比较结果
- 我们有可能在我们完成查找
.erl文件之前开始从erlcount_counter工作进程获得结果 - 有可能会有很多
erlcount_counter同时运行 - 我们很可能会在完成目录中的文件查找后继续获得结果(尤其是当我们有许多文件或复杂的正则表达式时)。
我们现在要考虑的两个主要问题是如何递归地遍历目录,同时仍然能够获得结果以便调度它们,以及如何在进行过程中接受结果,而不会造成混淆。
乍一看,最简单的方式是使用一个进程来实现返回结果的功能,因为它允许我们在递归中间返回结果。但是,仅仅为了能够在监督树中添加另一个进程,然后再让它们协同工作,而改变我们之前的结构有点烦人。事实上,有一种更简单的方法来做这些事情。
这是一种称为“继续传递风格”的编程风格。它的基本思想是将一个通常是深度递归的函数分解成每个步骤。我们返回每个步骤(通常是累加器),然后返回一个允许我们继续执行的函数。在本例中,我们的函数基本上将有两个可能的返回值
{continue, Name, NextFun}
done
每当我们收到第一个时,我们可以将 FileName 调度到 ppool 中,然后调用 NextFun 来继续寻找更多文件。我们可以将这个函数实现到 erlcount_lib 中
-module(erlcount_lib).
-export([find_erl/1]).
-include_lib("kernel/include/file.hrl").
%% Finds all files ending in .erl
find_erl(Directory) ->
find_erl(Directory, queue:new()).
啊,那里有什么新东西!真让人意外,我的心跳加速,血液沸腾。上面的包含文件是 file 模块提供给我们的。它包含一个记录(#file_info{}),其中包含许多字段,解释了有关文件的详细信息,包括它的类型、大小、权限等等。
我们的设计在这里包含一个队列。为什么呢?嗯,一个目录可能包含不止一个文件。因此,当我们遇到一个目录,它包含 15 个文件,我们想要处理第一个文件(如果它是一个目录,打开它,查看内部等等),然后处理剩下的 14 个文件。为了做到这一点,我们将把它们的名字存储在内存中,直到我们有时间处理它们。我们为此使用了一个队列,但是堆栈或任何其他数据结构仍然可以,因为我们并不关心读取文件的顺序。总之,重点是,这个队列有点像我们算法中文件的一个待办事项列表。
好了,让我们从读取第一次调用传递的第一个文件开始
%%% Private
%% Dispatches based on file type
find_erl(Name, Queue) ->
{ok, F = #file_info{}} = file:read_file_info(Name),
case F#file_info.type of
directory -> handle_directory(Name, Queue);
regular -> handle_regular_file(Name, Queue);
_Other -> dequeue_and_run(Queue)
end.
这个函数告诉我们一些事情:我们只想要处理普通文件和目录。在每种情况下,我们将编写一个函数来处理这些特定情况(handle_directory/2 和 handle_regular_file/2)。对于其他文件,我们将使用 dequeue_and_run/1 来出列之前准备好的任何东西(我们很快就会看到这个函数的作用)。现在,我们首先开始处理目录
%% Opens directories and enqueues files in there
handle_directory(Dir, Queue) ->
case file:list_dir(Dir) of
{ok, []} ->
dequeue_and_run(Queue);
{ok, Files} ->
dequeue_and_run(enqueue_many(Dir, Files, Queue))
end.
所以如果没有文件,我们将继续使用 dequeue_and_run/1 搜索,如果有许多文件,我们将把它们排队,然后再这样做。让我解释一下。函数 dequeue_and_run 将获取文件名队列,并从中获取一个元素。它从中获取的文件名将用于调用 find_erl(Name, Queue),然后我们继续执行,就像我们刚刚开始一样
%% Pops an item from the queue and runs it.
dequeue_and_run(Queue) ->
case queue:out(Queue) of
{empty, _} -> done;
{{value, File}, NewQueue} -> find_erl(File, NewQueue)
end.
请注意,如果队列为空({empty, _}),则该函数将自己视为 done(一个为我们的 CPS 函数选择的关键字),否则我们将再次继续执行。
我们必须考虑的另一个函数是 enqueue_many/3。它被设计为将给定目录中找到的所有文件排队,并按如下方式工作
%% Adds a bunch of items to the queue.
enqueue_many(Path, Files, Queue) ->
F = fun(File, Q) -> queue:in(filename:join(Path,File), Q) end,
lists:foldl(F, Queue, Files).
基本上,我们使用函数 filename:join/2 来合并目录的路径到每个文件名(以便我们获得完整的路径)。然后我们将这个新的完整路径添加到队列中的文件。我们使用折叠来对给定目录中的所有文件重复相同的过程。我们从其中得到的新的队列将被用来再次运行 find_erl/2,但这次我们将添加所有新发现的文件到待办事项列表中。
喔,我们有点跑题了。我们之前在做什么?哦,对了,我们正在处理目录,现在我们已经处理完了。接下来我们需要检查普通文件,以及它们是否以.erl结尾。
%% Checks if the file finishes in .erl
handle_regular_file(Name, Queue) ->
case filename:extension(Name) of
".erl" ->
{continue, Name, fun() -> dequeue_and_run(Queue) end};
_NonErl ->
dequeue_and_run(Queue)
end.
您可以看到,如果名称匹配(根据filename:extension/1),我们将返回我们的延续。延续将Name传递给调用者,然后将操作dequeue_and_run/1与要访问的文件队列包装成一个函数。这样,用户可以调用该函数并继续执行,就像我们仍然在递归调用中一样,同时仍然获得结果。如果文件名不以.erl结尾,那么用户就不希望我们返回结果,我们会继续出队更多文件。就是这样。
万岁,CPS 问题解决了。现在我们可以专注于另一个问题。我们该如何设计调度器,使其可以同时进行调度和接收?我的建议是使用有限状态机,您毫无疑问会接受,因为我是写这个文本的人。它将有两个状态。第一个状态是“调度”状态。只要我们等待我们的find_erl CPS 函数命中done条目,就会使用此状态。在此期间,我们永远不会考虑我们已经完成计数。这只会发生在第二个也是最后一个状态“监听”中,但我们仍然会一直接收来自 ppool 的通知。
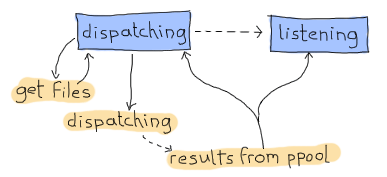
因此,这将需要我们拥有:
- 当我们收到要调度的新文件时,调度状态具有一个异步事件。
- 当我们完成获取新文件时,调度状态具有一个异步事件。
- 当我们完成获取新文件时,监听状态具有一个异步事件。
- 当 ppool 工作器完成运行正则表达式时,将发送一个全局事件。
我们将慢慢开始构建我们的 gen_fsm
-module(erlcount_dispatch).
-behaviour(gen_fsm).
-export([start_link/0, complete/4]).
-export([init/1, dispatching/2, listening/2, handle_event/3,
handle_sync_event/4, handle_info/3, terminate/3, code_change/4]).
-define(POOL, erlcount).
因此,我们的 API 将有两个函数:一个用于主管(start_link/0),另一个用于 ppool 调用者(complete/4,我们将在到达那里时看到参数)。其他函数是标准的 gen_fsm 回调函数,包括我们的listening/2和dispatching/2异步状态处理程序。我还定义了一个?POOL宏,用于为我们的 ppool 服务器指定名称“erlcount”。
那么 gen_fsm 的数据应该是什么样呢?由于我们要进行异步操作,并且将始终调用ppool:run_async/2而不是其他任何东西,因此我们实际上无法知道我们是否完成了文件调度。基本上,我们可能会有这样的时间线:
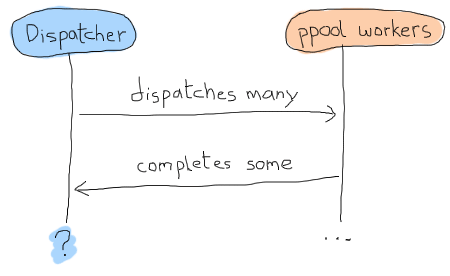
解决问题的一种方法是使用超时,但这总是很烦人:超时时间太长还是太短?是否发生了崩溃?这种不确定性可能和用柠檬做的牙刷一样有趣。相反,我们可以使用一个概念,即每个工作器都被赋予某种身份,我们可以跟踪并将其与回复关联起来,有点像进入“成功工作器”私人俱乐部的秘密密码。这个概念将让我们一对一地匹配我们收到的任何消息,并让我们知道我们什么时候绝对完成。现在我们知道了我们的状态数据可能是什么样子:
-record(data, {regex=[], refs=[]}).
第一个列表将是{RegularExpression, NumberOfOccurrences}形式的元组,而第二个列表将是某种消息引用的列表。任何东西都可以,只要它唯一。然后我们可以添加以下两个 API 函数:
%%% PUBLIC API
start_link() ->
gen_fsm:start_link(?MODULE, [], []).
complete(Pid, Regex, Ref, Count) ->
gen_fsm:send_all_state_event(Pid, {complete, Regex, Ref, Count}).
这里就是我们的秘密complete/4函数。不出所料,工作器只需要发回三条数据:他们正在运行的正则表达式、他们的关联分数以及上面提到的引用。太棒了,我们可以进入真正有趣的内容了!
init([]) ->
%% Move the get_env stuff to the supervisor's init.
{ok, Re} = application:get_env(regex),
{ok, Dir} = application:get_env(directory),
{ok, MaxFiles} = application:get_env(max_files),
ppool:start_pool(?POOL, MaxFiles, {erlcount_counter, start_link, []}),
case lists:all(fun valid_regex/1, Re) of
true ->
self() ! {start, Dir},
{ok, dispatching, #data{regex=[{R,0} || R <- Re]}};
false ->
{stop, invalid_regex}
end.
init 函数首先从应用程序文件加载我们运行所需的所有信息。完成此操作后,我们计划使用erlcount_counter作为回调模块来启动进程池。在实际开始之前,最后一步是确保所有正则表达式都是有效的。这样做的原因很简单。如果我们现在不进行检查,则必须在其他地方添加错误处理调用。这很可能是在erlcount_counter工作器中。如果在那里发生,我们现在必须定义当工作器因该问题而开始崩溃时该怎么办。在启动应用程序时处理起来更简单。以下是valid_regex/1函数:
valid_regex(Re) ->
try re:run("", Re) of
_ -> true
catch
error:badarg -> false
end.
我们只尝试在空字符串上运行正则表达式。这将不会花费任何时间,并让re模块尝试运行这些东西。因此正则表达式是有效的,我们通过向自己发送{start, Directory}并使用[{R,0} || R <- Re]定义的状态来启动应用程序。这基本上会将[a,b,c]形式的列表更改为[{a,0},{b,0},{c,0}]形式,目的是为每个正则表达式添加一个计数器。
我们必须处理的第一个消息是handle_info/2中的{start, Dir}。请记住,由于 Erlang 的行为几乎完全基于消息,因此如果我们想要触发函数调用并按照我们的方式做事,我们必须执行向自己发送消息的丑陋步骤。很烦人,但可以管理。
handle_info({start, Dir}, State, Data) ->
gen_fsm:send_event(self(), erlcount_lib:find_erl(Dir)),
{next_state, State, Data}.
我们向自己发送erlcount_lib:find_erl(Dir)的结果。它将在dispatching中被接收,因为这是State的值,它由 FSM 的init函数设置。这段代码解决了我们的问题,但也说明了我们在整个 FSM 中将采用的通用模式。由于我们的find_erl/1函数是用 Continuation-Passing Style 编写的,因此我们可以向自己发送异步事件,并在每个正确的回调状态中处理它。我们的延续的第一个结果很可能是{continue, File, Fun}。我们也将处于“调度”状态,因为这是我们在 init 函数中作为初始状态设置的。
dispatching({continue, File, Continuation}, Data = #data{regex=Re, refs=Refs}) ->
F = fun({Regex, _Count}, NewRefs) ->
Ref = make_ref(),
ppool:async_queue(?POOL, [self(), Ref, File, Regex]),
[Ref|NewRefs]
end,
NewRefs = lists:foldl(F, Refs, Re),
gen_fsm:send_event(self(), Continuation()),
{next_state, dispatching, Data#data{refs = NewRefs}};
这有点难看。对于每个正则表达式,我们创建一个唯一的引用,调度一个知道此引用的 ppool 工作器,然后存储此引用(以了解工作器是否已完成)。我选择在 foldl 中执行此操作,以使其更易于累积所有新引用。完成调度后,我们再次调用延续以获取更多结果,然后使用新的引用作为我们的状态等待下一条消息。
我们还能收到哪种类型的消息?我们这里有两个选择。要么没有一个工作器给我们发回结果(即使他们尚未实现),要么我们收到done消息,因为所有文件都已查找。让我们继续第二种类型,以完成dispatching/2函数的实现。
dispatching(done, Data) ->
%% This is a special case. We can not assume that all messages have NOT
%% been received by the time we hit 'done'. As such, we directly move to
%% listening/2 without waiting for an external event.
listening(done, Data).
注释非常明确地说明了正在发生的事情,但无论如何让我解释一下。当我们安排作业时,我们可以在dispatching/2或listening/2中接收结果。这可以采用以下形式:
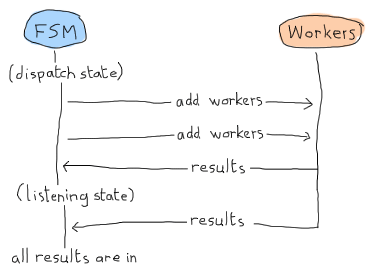
在这种情况下,“监听”状态可以只等待结果,并宣布一切都在内。但请记住,这是 Erlang Land(Erland),我们并行且异步地工作!这种情况也可能发生:
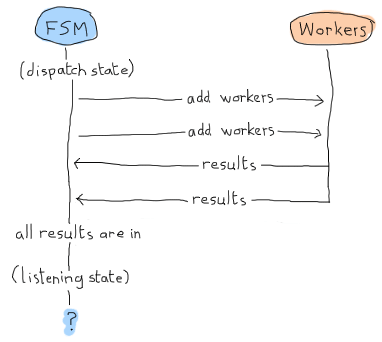
哎呀。我们的应用程序将永远挂起,等待消息。这就是为什么我们需要手动调用listening/2的原因:我们将强制它执行某种结果检测,以确保所有内容都已接收,以防我们已经拥有所有结果。以下是它的样子:
listening(done, #data{regex=Re, refs=[]}) -> % all received!
[io:format("Regex ~s has ~p results~n", [R,C]) || {R, C} <- Re],
{stop, normal, done};
listening(done, Data) -> % entries still missing
{next_state, listening, Data}.
如果没有剩余的refs,那么一切都已接收,我们可以输出结果。否则,我们可以继续监听消息。如果您再看一下complete/4和这个图表:
结果消息是全局的,因为它们可以在“调度”或“监听”状态中接收。以下是实现:
handle_event({complete, Regex, Ref, Count}, State, Data = #data{regex=Re, refs=Refs}) ->
{Regex, OldCount} = lists:keyfind(Regex, 1, Re),
NewRe = lists:keyreplace(Regex, 1, Re, {Regex, OldCount+Count}),
NewData = Data#data{regex=NewRe, refs=Refs--[Ref]},
case State of
dispatching ->
{next_state, dispatching, NewData};
listening ->
listening(done, NewData)
end.
首先,它在Re列表中找到刚刚完成的正则表达式,该列表还包含所有正则表达式的计数。我们提取该值(OldCount),并使用lists:keyreplace/4将其与新计数(OldCount+Count)更新。我们使用新的分数更新我们的Data记录,同时删除工作器的Ref,然后向自己发送下一个状态。
在普通的 FSM 中,我们只需要执行{next_state, State, NewData},但在这里,由于关于何时完成或不完成的问题,我们必须再次手动调用listening/2。真是太痛苦了,但这是一个必要的步骤。
调度器就到此为止了。我们只需添加其余的填充行为函数:
handle_sync_event(Event, _From, State, Data) ->
io:format("Unexpected event: ~p~n", [Event]),
{next_state, State, Data}.
terminate(_Reason, _State, _Data) ->
ok.
code_change(_OldVsn, State, Data, _Extra) ->
{ok, State, Data}.
然后我们可以继续进行计数器。你可能想先休息一下。铁杆读者可以自己举重几次来放松自己,然后回来继续学习。
计数器
计数器比调度器更简单。虽然我们仍然需要一个行为来执行操作(在本例中是 gen_server),但它将非常简洁。我们只需要它做三件事:
- 打开文件
- 对其运行正则表达式并计数实例
- 发回结果。
对于第一点,file中有很多函数可以帮助我们做到这一点。对于第 3 点,我们定义了erlcount_dispatch:complete/4来执行此操作。对于第 2 点,我们可以使用re模块和run/2-3,但它不能完全满足我们的需求。
1> re:run(<<"brutally kill your children (in Erlang)">>, "a").
{match,[{4,1}]}
2> re:run(<<"brutally kill your children (in Erlang)">>, "a", [global]).
{match,[[{4,1}],[{35,1}]]}
3> re:run(<<"brutally kill your children (in Erlang)">>, "a", [global, {capture, all, list}]).
{match,[["a"],["a"]]}
4> re:run(<<"brutally kill your children (in Erlang)">>, "child", [global, {capture, all, list}]).
{match,[["child"]]}
虽然它确实接受了我们需要的参数(re:run(String, Pattern, Options)),但它没有给出正确的计数。让我们将以下函数添加到erlcount_lib中,以便我们可以开始编写计数器。
regex_count(Re, Str) ->
case re:run(Str, Re, [global]) of
nomatch -> 0;
{match, List} -> length(List)
end.
它基本上只是计算结果并返回。别忘了将其添加到导出表单中。
好的,让我们继续进行工作器。
-module(erlcount_counter).
-behaviour(gen_server).
-export([start_link/4]).
-export([init/1, handle_call/3, handle_cast/2, handle_info/2,
terminate/2, code_change/3]).
-record(state, {dispatcher, ref, file, re}).
start_link(DispatcherPid, Ref, FileName, Regex) ->
gen_server:start_link(?MODULE, [DispatcherPid, Ref, FileName, Regex], []).
init([DispatcherPid, Ref, FileName, Regex]) ->
self() ! start,
{ok, #state{dispatcher=DispatcherPid,
ref = Ref,
file = FileName,
re = Regex}}.
handle_call(_Msg, _From, State) ->
{noreply, State}.
handle_cast(_Msg, State) ->
{noreply, State}.
handle_info(start, S = #state{re=Re, ref=Ref}) ->
{ok, Bin} = file:read_file(S#state.file),
Count = erlcount_lib:regex_count(Re, Bin),
erlcount_dispatch:complete(S#state.dispatcher, Re, Ref, Count),
{stop, normal, S}.
terminate(_Reason, _State) ->
ok.
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
这里有两个有趣的部分:init/1回调函数,我们命令自己开始,然后是一个单一的handle_info/2子句,我们在这个子句中打开文件(file:read_file(Name)),获取一个二进制文件,将其传递给我们的新regex_count/2函数,然后使用complete/4将其发回。然后我们停止工作器。其余的只是标准的 OTP 回调内容。
现在我们可以编译并运行整个程序了!
$ erl -make Recompile: src/erlcount_sup Recompile: src/erlcount_lib Recompile: src/erlcount_dispatch Recompile: src/erlcount_counter Recompile: src/erlcount Recompile: test/erlcount_tests
太棒了。打开香槟,因为我们没有抱怨!
运行应用程序运行
有很多方法可以运行我们的应用程序。确保您位于一个目录中,您在该目录中以某种方式拥有这两个目录并排放置:
erlcount-1.0 ppool-1.0
现在以以下方式启动 Erlang:
$ erl -env ERL_LIBS "."
ERL_LIBS变量是您环境中定义的一个特殊变量,它允许您指定 Erlang 在哪里可以找到 OTP 应用程序。然后,VM 能够自动在其中查找ebin/目录。erl还可以接受-env NameOFVar Value形式的参数来快速覆盖此设置,因此这就是我在这里使用的。ERL_LIBS变量非常有用,尤其是在安装库时,所以请记住它!
使用我们启动的 VM,我们可以测试所有模块是否都在那里:
1> application:load(ppool). ok
此函数将尝试在内存中加载所有应用程序模块,如果可以找到它们。如果您不调用它,它将在启动应用程序时自动完成,但这提供了一种测试我们路径的简便方法。我们可以启动应用程序:
2> application:start(ppool), application:start(erlcount). ok Regex if\s.+-> has 20 results Regex case\s.+\sof has 26 results
您的结果可能因目录中的内容而异。请注意,根据文件数量,这可能需要更长时间。

那么,如果我们希望为应用程序设置不同的变量呢?我们需要一直更改应用程序文件吗? 不需要!Erlang 也支持这一点。假设我想看看 Erlang 程序员在源代码文件中生气了多少次?
erl 可执行文件支持一组特殊的参数,格式为 -AppName Key1 Val1 Key2 Val2 ... KeyN ValN。在这种情况下,我们可以对来自 R14B02 发行版的 Erlang 源代码运行以下正则表达式,使用 2 个正则表达式,如下所示
$ erl -env ERL_LIBS "." -erlcount directory '"/home/ferd/otp_src_R14B02/lib/"' regex '["shit","damn"]' ... 1> application:start(ppool), application:start(erlcount). ok Regex shit has 3 results Regex damn has 1 results 2> q(). ok
请注意,在本例中,我作为参数提供的所有表达式都用单引号 (') 括起来。这是因为我希望它们被我的 Unix shell 按字面意思理解。不同的 shell 可能有不同的规则。
我们也可以尝试使用更通用的表达式(允许值以大写字母开头)以及更多允许的文件描述符来进行搜索
$ erl -env ERL_LIBS "." -erlcount directory '"/home/ferd/otp_src_R14B02/lib/"' regex '["[Ss]hit","[Dd]amn"]' max_files 50 ... 1> application:start(ppool), application:start(erlcount). ok Regex [Ss]hit has 13 results Regex [Dd]amn has 6 results 2> q(). ok
哦,OTP 程序员。是什么让你们如此生气? (“使用 Erlang”不是一个可以接受的答案)
由于需要对数百个文件进行更复杂的检查,因此此操作可能需要更长时间才能完成。这都很好用,但这里有一些烦人的事情。为什么我们总是手动启动这两个应用程序?难道没有更好的方法吗?
包含的应用程序
包含的应用程序是使事情正常工作的一种方法。包含应用程序的基本理念是,您将一个应用程序(在本例中为 ppool)定义为另一个应用程序(此处为 erlcount)的一部分。为此,需要对这两个应用程序进行一些更改。
它的要点是修改您的应用程序文件,然后需要向它们添加称为 *启动阶段* 的内容,等等。

越来越建议**不要**使用包含的应用程序,原因很简单:它们严重限制了代码重用。这样想吧。我们花了大量时间来完善 ppool 的架构,使其任何人都可以使用,获得自己的池,并可以自由地使用它。如果我们将其推入一个包含的应用程序中,那么它就不能再包含在这个 VM 上的任何其他应用程序中,如果 erlcount 崩溃,那么 ppool 将与其一起被关闭,从而破坏任何想要使用 ppool 的第三方应用程序的工作。
出于这些原因,包含的应用程序通常被许多 Erlang 程序员的工具箱排除在外。正如我们将在下一章中看到的那样,发行版基本上可以帮助我们以更通用的方式完成相同的事情(甚至更多)。
在此之前,我们还需要讨论一个与应用程序相关的主题。
复杂终止
在某些情况下,我们需要在终止应用程序之前执行更多步骤。应用程序回调模块中的 stop/1 函数可能不够用,尤其是在它在应用程序已终止后被调用时。如果我们需要在应用程序实际消失之前清理某些内容,该怎么办?
诀窍很简单。只需在应用程序回调模块中添加一个函数 prep_stop(State)。 State 将是您的 start/2 函数返回的状态,prep_stop/1 返回的内容将传递给 stop/1。因此,函数 prep_stop/1 技术上在 start/2 和 stop/1 之间插入,并在应用程序仍然存活但即将关闭时执行。
您需要使用这种回调时会知道它,但我们现在不需要为我们的应用程序使用它。
不要喝太多酷乐 aid
当我帮助 Yurii Rashkosvkii (yrashk) 调试 agner(Erlang 的包管理器)的问题时,我遇到了 prep_stop/1 回调的一个真实用例。遇到的问题有点复杂,与 simple_one_for_one 监督程序和应用程序主控之间的奇怪交互有关,因此您可以随意跳过本文的这一部分。
Agner 的基本结构是,应用程序启动,启动一个顶层监督程序,该监督程序启动一个服务器和另一个监督程序,该监督程序反过来又生成动态子进程
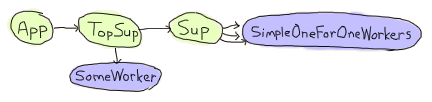
现在问题在于,文档说以下内容
关于简单一对一监督程序的重要说明:无论关闭策略如何,简单一对一监督程序的动态创建的子进程都不会被显式杀死,而是预计在监督程序关闭时终止(即,当接收到来自父进程的退出信号时)。
事实确实如此。监督程序只杀死其常规子进程,然后消失,将其留给简单一对一子进程的行为以捕获退出消息并离开。仅此而已,没有问题。
如前所述,对于每个应用程序,我们都有一个应用程序主控。这个应用程序主控充当组长。提醒一下,应用程序主控与其父进程(应用程序控制器)及其直接子进程(应用程序的顶层监督程序)链接并监控它们。当它们中的任何一个失败时,主控会终止自己的执行,利用其作为组长的状态来终止所有剩余的子进程。同样,仅此而已,没有问题。
但是,如果您将这两个特性混合在一起,然后决定使用 application:stop(agner) 关闭应用程序,您将陷入非常棘手的情况
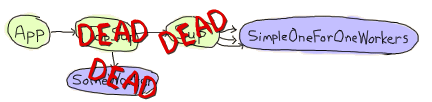
在此时,两个监督程序都已死亡,应用程序中的常规工作程序也已死亡。简单一对一工作程序目前正在死亡,每个工作程序都接收到其直接祖先发送的 EXIT 信号。
但是,与此同时,应用程序主控发现其直接子进程已死亡,并最终杀死了所有尚未死亡的简单一对一工作程序。
结果是一堆设法自行清理的工作程序,以及一堆未能做到这一点的工作程序。这高度依赖于时间,难以调试,但很容易修复。
我和 Yurii 基本上通过使用 ApplicationCallback:prep_stop(State) 函数获取所有动态简单一对一子进程的列表,监控它们,然后在 stop(State) 回调函数中等待它们全部死亡来解决这个问题。这迫使应用程序控制器保持活动状态,直到所有动态子进程都死亡。您可以在 Agner 的 GitHub 存储库 上看到实际的文件

真是个丑陋的东西!希望人们很少遇到这种问题,希望您也不会遇到。您可以用肥皂洗眼睛,洗掉使用 prep_stop/1 使事情正常工作的可怕画面,即使有时它很有意义并且是可取的。回来后,我们将开始考虑将应用程序打包到发行版中。
更新
从 R15B 版本开始,上述问题已解决。在监督程序关闭的情况下,动态子进程的终止似乎是同步的。