分布式宝典
独自在黑暗中
哦,你好!请坐。我在等你。当你第一次听说 Erlang 时,可能有两个或三个属性吸引了你。Erlang 是一种函数式语言,它具有出色的并发语义,并且支持分布式。我们现在已经看到了前两个属性,花时间探索了十几个你可能没有预料到的属性,现在我们来到了最后一个重要的事情,分布式。
我们在来到这里之前等了相当长一段时间,因为如果我们不能首先在本地让事情正常运行,那么分布式就没有什么用处。我们终于胜任了这项任务,并已经走过了漫长的道路才走到今天。就像 Erlang 的几乎所有其他功能一样,该语言的分布式层最初是为了提供容错性而添加的。在单台机器上运行的软件总是存在单台机器死机并导致应用程序离线的风险。在多台机器上运行的软件可以更容易地处理硬件故障,如果,且仅当应用程序构建正确时。如果您的应用程序运行在多台服务器上,但无法处理其中一台服务器被关闭,那么在容错性方面确实没有好处。

看,分布式编程就像一个人孤身一人在黑暗中,周围都是怪物。这很可怕,你不知道该做什么或什么在向你袭来。坏消息是,分布式 Erlang 仍然让你独自一人在黑暗中与可怕的怪物战斗。它不会为你做任何那种艰苦的工作。好消息是,Erlang 不仅给你留下了零钱和糟糕的瞄准能力来杀死怪物,还给你提供了手电筒、砍刀和帅气的胡子,让你更有自信(这也适用于女性读者)。
这并不是因为 Erlang 的编写方式,而是因为分布式软件的本质。Erlang 将编写分布式的几个基本构建块:让多个节点(虚拟机)相互通信的方式、在通信中序列化和反序列化数据、将多个进程的概念扩展到多个节点、监视网络故障的方式,等等。但是,它不会提供针对特定于软件问题的解决方案,例如“当东西崩溃时会发生什么”。
这是我们在 OTP 中之前见过的标准“工具,而不是解决方案”方法;你很少得到完整的软件和应用程序,但你会得到很多用来构建系统的组件。你将拥有能够告诉你系统部分何时启动或停止的工具,拥有能够在网络上做很多事情的工具,但几乎没有能够为你解决问题的银弹。
让我们看看我们能用这些工具做些什么。
这是我的“大杀器”
为了解决所有这些黑暗中的怪物,我们得到了一个非常有用的东西:相当完整的网络透明度。
一个正在运行的 Erlang 虚拟机实例,准备连接到其他虚拟机,称为节点。虽然某些语言或社区会认为服务器是一个节点,但在 Erlang 中,每个 VM 都是一个节点。因此,你可以在一台计算机上运行 50 个节点,或者在 50 台计算机上运行 50 个节点。这并不重要。
当你启动一个节点时,你给它一个名称,它将连接到一个名为EPMD(Erlang 端口映射守护进程)的应用程序,该应用程序将在你的 Erlang 集群中的每台计算机上运行。EPMD 将充当名称服务器,允许节点注册自己,联系其他节点,并在存在任何名称冲突时向你发出警告。
从这一点开始,一个节点可以决定建立与另一个节点的连接。当它这样做时,两个节点都会自动开始相互监视,它们可以知道连接是否断开,或者节点是否消失。更重要的是,当一个新节点加入到已经连接到一组节点的另一个节点时,新节点将连接到整个组。
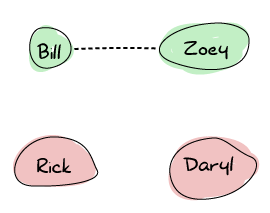
让我们以僵尸爆发期间一群幸存者为例,来说明 Erlang 节点如何建立它们的连接。我们有 Zoey、Bill、Rick 和 Daryl。Zoey 和 Bill 彼此认识,并在对讲机上使用相同的频率进行交流。Rick 和 Daryl 都是独立的
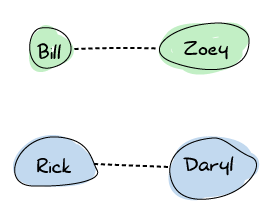
现在假设 Rick 和 Daryl 在前往幸存者营地的路上相遇了。他们共享他们的对讲机频率,现在可以在再次分开之前保持最新消息。
在某个时刻,Rick 遇到了 Bill。他们都对此感到非常高兴,于是他们决定共享频率。此时,连接蔓延,最终图如下所示
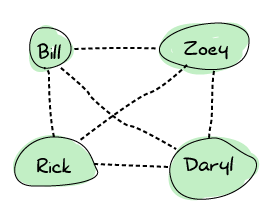
这意味着任何幸存者都可以直接联系任何其他人。这很有用,因为如果任何幸存者死亡,都不会有人被孤立。Erlang 节点以完全相同的方式设置:每个人都连接到每个人。
不要喝太多酷乐助
这种做事方式,虽然对于某些容错性原因来说很好,但有一个相当糟糕的缺点,即你能扩展的程度。仅仅因为需要多少连接和多少闲聊,要让数百个节点成为你的 Erlang 集群的一部分将会很困难。实际上,你需要为你要连接的每个节点提供一个端口。
如果你打算使用 Erlang 进行这种繁重的设置,请继续阅读本章,我们将了解为什么事情是这样的,以及如果可能的话,可以采取哪些措施来解决这个问题。
一旦节点相互连接,它们就保持完全独立:它们保留自己的进程注册表,自己的 ETS 表(使用自己的表名),它们加载的模块彼此独立。一个崩溃的连接节点不会导致与其连接的节点崩溃。
连接的节点然后可以开始交换消息。Erlang 的分布式模型被设计为本地进程可以联系远程进程并向其发送常规消息。如果没有任何东西是共享的,并且所有进程注册表都是唯一的,那么这是如何可能的?正如我们将在稍后讨论分布式的细节时看到的那样,有一种方法可以访问特定节点上的注册进程。从那时起,可以发送第一条消息。
Erlang 消息将以透明的方式自动为你序列化和反序列化。所有数据结构,包括 pid,在远程和本地都将以相同的方式工作。这意味着我们可以通过网络发送 pid,然后与它们通信,发送消息,等等。更棒的是,如果你可以访问 pid,就可以在网络上设置链接和监视器!
所以如果 Erlang 竭尽全力使一切透明,为什么我说它只给了我们一把砍刀、一个手电筒和一个胡子呢?
分布式计算的谬误
就像一把砍刀只用于杀死特定类型的怪物一样,Erlang 的工具只用于处理某些类型的分布式计算。为了理解 Erlang 提供给我们的工具,首先了解分布式世界中的环境类型以及 Erlang 为提供容错性而做出的假设将很有用。
一些非常聪明的人在过去的几十年里花时间对分布式计算中出错的类型进行了分类。他们提出了人们做出的 8 个主要假设,这些假设最终会导致他们以后陷入困境,其中一些是 Erlang 的设计人员出于各种原因做出的假设。
网络可靠
分布式计算的第一个谬误是假设应用程序可以分布在网络上。这有点奇怪,但网络会因为很多令人讨厌的原因而宕机:电源故障、硬件损坏、有人踩到电线、通往其他维度的漩涡吞噬关键任务组件、脑虫入侵、铜线被盗等等。
因此,你能犯的最大错误之一就是认为你可以访问远程节点并与它们通信。这在某种程度上可以通过添加更多硬件并获得冗余来解决,这样如果某些硬件发生故障,应用程序仍然可以在其他地方访问。另一种方法是准备好忍受消息和请求的丢失,准备好应对响应不灵的情况。当你的软件堆栈运行良好,但你依赖于某些不再存在的第三方服务时,尤其如此。
Erlang 没有采取任何特殊措施来处理这个问题,因为它通常是应用程序特定的决策。毕竟,除了你之外,还有谁知道特定组件有多重要?尽管如此,你并不孤单,因为分布式 Erlang 节点将能够检测到其他节点断开连接(或变得无响应)。有一些特定函数用于监视节点,链接和监视器也会在断开连接时触发。
即使这样,Erlang 在这种情况下最强大的功能是其异步通信模式。通过异步发送消息,并强制开发人员在事情进展顺利时发送回复,Erlang 推动所有消息传递活动直观地处理失败。如果与你通信的进程位于由于网络故障而消失的节点上,我们将像处理任何本地崩溃一样自然地处理它。这是 Erlang 据说可以很好地扩展(在性能方面扩展,在设计方面也扩展)的众多原因之一。
不要喝太多酷乐助
跨节点的链接和监视可能很危险。在网络故障的情况下,所有远程链接和监视器都会立即触发。这可能会向各种进程生成数千条信号和消息,从而给系统带来沉重而意想不到的负载。
为不可靠的网络做好准备,也意味着为突然发生的故障做好准备,并确保你的系统不会因系统的一部分突然消失而瘫痪。
没有延迟
看似良好的分布式系统的双刃剑方面之一是,它们通常会隐藏你正在进行的函数调用是远程的这一事实。虽然你希望某些函数调用非常快,但通过网络进行调用完全不同。这就像在比萨店里点比萨和从另一个城市送到你家一样。虽然总会有一个基本等待时间,但在一种情况下,你的比萨可能会冷了,因为它送达时间过长。
忘记网络通信会使即使是最小的消息也变慢,如果你总是期望获得非常快的结果,这是一个代价高昂的错误。Erlang 的模型在这方面对我们很友好。由于我们使用隔离的进程、异步消息、超时和始终考虑进程失败的可能性来设置我们的本地应用程序的方式,因此很少需要适应分布式:超时、链接、监视器和异步模式保持不变,并且仍然可靠。我们从一开始就预料到了这种问题,因此 Erlang 隐式地不假设没有延迟。
但是,你可能会在你的设计中做出这种假设,并期望回复比实际可能的速度更快。请注意这一点。
带宽无限
尽管网络传输速度越来越快,而且一般来说,随着时间的推移,每个通过网络传输的字节都更便宜,但假设发送大量数据既简单又容易是有风险的。
一般来说,由于我们本地构建应用程序的方式,我们在 Erlang 中不会遇到太多这方面的问题。请记住,一个好方法是发送有关正在发生的事情的消息,而不是四处移动新的状态(“玩家 X 找到了物品 Y”,而不是一遍又一遍地发送玩家 X 的整个物品清单)。
如果由于某种原因,您需要发送大型消息,请务必格外小心。Erlang 分布式和通信在许多节点上工作的方式对大型消息特别敏感。如果两个节点相互连接,它们的所有通信都倾向于通过单个 TCP 连接进行。由于我们通常希望在两个进程之间(即使跨网络)保持消息排序,因此消息将按顺序通过连接发送。这意味着,如果您有一条非常大的消息,您可能会阻塞该通道以接收所有其他消息。
更糟糕的是,Erlang 通过发送称为“心跳”的东西来了解节点是存活还是死亡。心跳是定期发送给两个节点之间的小型消息,基本上是在说“我还活着,继续保持下去!”。它们就像我们的僵尸幸存者定期互相发送消息一样;“比尔,你在那里吗?”如果比尔从未回复,那么你可能会认为他死了(或没电了),并且你将无法收到他未来的通信。无论如何,心跳通过与常规消息相同的通道发送。
问题是大型消息可能会因此阻碍心跳。太多的大型消息长时间地让心跳处于封锁状态,最终其中一个节点会认为另一个节点没有响应,并断开彼此的连接。这很糟糕。无论如何,防止这种情况发生的良好 Erlang 设计教训是保持消息小巧。这样一切都会更好。
网络是安全的
当您进行分布式部署时,相信一切都安全,您可以信任收到的消息,这往往非常危险。它可能是像有人意外地伪造消息并将其发送给您,有人拦截数据包并修改它们(或查看敏感数据),或者在最糟糕的情况下,有人能够接管您的应用程序或其运行的系统等简单的事情。
在分布式 Erlang 的情况下,这令人遗憾地成为了一种假设。以下是 Erlang 的安全模型的外观
* 此空间有意保留空白 *
是的。这是因为 Erlang 分布式最初是为容错和组件冗余而设计的。在该语言的早期,当它用于电话交换机和其他电信应用时,Erlang 经常部署在以最奇怪的方式运行的硬件上——非常偏远的地方,环境很奇怪(工程师有时必须将服务器连接到墙上以避免潮湿的地面,或在树林里安装定制的加热系统以使硬件在最佳温度下运行)。在这些情况下,您有故障转移硬件作为主硬件的同一物理位置的一部分。这通常是分布式 Erlang 运行的地方,这也解释了为什么 Erlang 设计人员假设了一个安全的网络来操作。
不幸的是,这意味着现代 Erlang 应用程序很少能够跨不同的数据中心进行集群。实际上,不建议这样做。大多数情况下,您希望您的系统基于许多较小的、隔离的 Erlang 节点集群,通常位于单个位置。任何更复杂的事情都需要由开发人员来处理:要么切换到 SSL,实现他们自己的高级通信层,通过安全通道进行隧道传输,或者重新实现节点之间的通信协议。有关如何执行此操作的指针存在于 ERTS 用户指南中,在 如何为 Erlang 分布式实现备用载体 中。有关分布式协议的更多详细信息包含在 分布式协议 中。即使在这些情况下,您也必须非常小心,因为有人获得对其中一个分布式节点的访问权限,那么他们就可以访问所有节点,并且可以运行他们可以运行的任何命令。
拓扑不会改变
在最初设计用于在许多服务器上运行的分布式应用程序时,您可能会想到一定数量的服务器,也许还想到了一组给定的主机名。也许您会使用特定的 IP 地址进行设计。这可能是一个错误。硬件会损坏,运维人员会移动服务器,会添加新机器,有些机器会被移除。网络拓扑结构将不断变化。如果您的应用程序使用任何这些硬编码的拓扑细节,那么它将无法轻松地处理网络中的这些变化。
在 Erlang 的情况下,没有以这种方式做出任何明确的假设。但是,让它潜入您的应用程序非常容易。Erlang 节点都有一个名称和一个主机名,并且它们可以不断变化。对于 Erlang 进程,您不仅要考虑进程的命名方式,还要考虑它现在在集群中的位置。如果您硬编码名称和主机,那么您可能在下次故障时会遇到麻烦。不过,别担心太多,因为我们将在后面看到一些有趣的库,它们让我们忘记节点名称和拓扑结构,同时仍然能够定位特定进程。
只有一个管理员
无论如何,这是语言或库的分布式层无法为您准备的。这种谬论的思想是,您并不总是只有一个软件及其服务器的主要操作员,尽管它可能是像只有一个操作员一样设计的。如果您决定在一台计算机上运行多个节点,那么您可能永远不必关心这种谬论。但是,如果您跨不同位置运行东西,或者第三方依赖于您的代码,那么您就必须注意。
需要注意的事情包括为其他人提供诊断系统问题的工具。Erlang 在您可以手动操作 VM 时,调试起来比较容易——毕竟,您甚至可以在需要时动态地重新加载代码。但是,无法访问您的终端并坐在节点前面的人需要不同的设施来操作。
这种谬论的另一个方面是,诸如重启服务器、在数据中心之间移动实例或升级软件堆栈的各个部分,并不一定是只有一个人或一个团队控制的。在非常大型的软件项目中,实际上很可能许多团队,甚至许多不同的软件公司,会负责整个系统的不同部分。
如果您正在为您的软件堆栈编写协议,则可能需要能够处理该协议的多个版本,这取决于您的用户和合作伙伴升级代码的速度。协议可能从一开始就包含有关其版本控制的信息,或者能够在事务进行过程中进行更改,具体取决于您的需求。我相信您可以想到更多可能会出错的事情的示例。
传输成本为零
这是一个双方面的假设。第一个假设与数据传输的时间成本有关,第二个假设与数据传输的资金成本有关。
第一种情况假设执行诸如序列化数据之类的操作几乎是免费的,非常快,并且没有发挥很大的作用。实际上,较大的数据结构比较小的数据结构需要更长的时间来序列化,然后需要在网络的另一端进行反序列化。无论您在网络中传输什么,情况都会如此。小型消息将有助于减少这种效果的明显程度。
假设传输成本为零的第二个方面与传输数据的成本有关。在现代服务器堆栈中,内存(包括 RAM 和磁盘中的内存)通常比带宽成本便宜,而带宽成本是您必须持续支付的,除非您拥有运行这些东西的整个网络。在这种情况下,优化以减少使用更少请求的小型消息将是有益的。
对于 Erlang,由于其最初的使用案例,没有特别注意执行诸如压缩跨节点传输的消息之类的操作(尽管该功能已经存在)。相反,原始的设计人员选择让人们根据需要实现他们自己的通信层。因此,程序员有责任确保发送小型消息并采取其他措施来最大程度地减少传输数据的成本。
网络是同构的
最后一个假设是认为网络应用程序的所有组件都会说同一种语言,或者会使用相同的格式协同工作。
对于我们的僵尸幸存者,这可能是一个问题,即不要假设所有幸存者在制定计划时都会说英语(或流利的英语),或者一个词对不同的人有不同的含义。

在编程方面,这通常是不要依赖封闭标准,而是使用开放标准,或者准备在任何时候从一种协议切换到另一种协议。在 Erlang 中,分布式协议是完全公开的,但所有 Erlang 节点都假设与它们通信的人会说同一种语言。试图融入 Erlang 集群的外国人要么必须学会说 Erlang 的协议,要么 Erlang 应用程序需要某种用于 XML、JSON 或其他内容的翻译层。
如果它像鸭子一样嘎嘎叫,而且像鸭子一样行走,那么它一定是一只鸭子。这就是我们有 C-节点 的原因。C-节点(或使用 C 以外的其他语言的节点)建立在任何语言和应用程序都可以实现 Erlang 协议,然后假装它是集群中的 Erlang 节点的思想之上。
另一种用于数据交换的解决方案是使用称为 BERT 或 BERT-RPC 的东西。这是一种类似于 XML 或 JSON 的交换格式,但指定为类似于 Erlang 外部项格式 的东西。
简而言之,您始终需要注意以下几点
- 您不应该假设网络是可靠的。Erlang 除了检测到出现错误之外,没有任何特殊措施(尽管这作为一个功能还不错)。
- 网络可能会偶尔变慢。Erlang 提供异步机制,并且了解这一点,但是您必须小心,以确保您的应用程序不会违背这一点并破坏它。
- 带宽不是无限的。小型、描述性的消息有助于尊重这一点。
- 网络并不安全,而且 Erlang 默认情况下没有任何东西可以提供。
- 网络拓扑可能会发生变化。Erlang 没有做出任何明确的假设,但是您可能会对事物所在的位置以及它们的命名方式做出一些假设。
- 您(或您的组织)很少完全控制事物的结构。您的系统的一部分可能已过时,使用不同的版本,在您不期望的时候重启或关闭。
- 传输数据有成本。同样,小型、简短的消息有所帮助。
- 网络是异构的。并非所有事物都相同,并且数据交换应该依赖于记录良好的格式。
注意:分布式计算的谬论是在 分布式计算谬论详解 中由 *Arnon Rotem-Gal-Oz* 提出的。
生或死
理解分布式计算的谬误应该部分解释了为什么我们在黑暗中与怪物作战,但有了更好的工具。仍然有很多问题和事情需要我们去做。其中许多是关于上述谬误的谨慎的设计决策(小消息、减少通信等)。最棘手的问题与节点死亡或网络不可靠有关。这尤其令人讨厌,因为没有好的方法来知道某样东西是死是活(无法与其联系)。
让我们回到比尔、佐伊、瑞克和达里尔,我们的 4 位僵尸末日幸存者。他们在安全屋相遇,在那里休息了几天,吃着他们能找到的任何罐头食品。过了一段时间,他们不得不搬出去,分散到城里寻找更多资源。他们在他们所在的这个小镇边缘的一个小营地里设定了一个会合点。
在探险过程中,他们通过对讲机保持联系。他们宣布他们的发现,清理路径,也许他们找到了新的幸存者。
现在假设在安全屋和会合点之间,瑞克试图联系他的战友。他设法打电话给比尔和佐伊,与他们交谈,但达里尔无法联系。比尔和佐伊也联系不上他。问题是,根本无法知道达里尔是被僵尸吞噬了,还是电池没电了,还是睡着了,还是在地下。
该小组必须决定是否继续等待他,继续呼叫一段时间,还是假设他死了并继续前进。
分布式系统中的节点也存在同样的困境。当一个节点变得无响应时,它是由于硬件故障消失了吗?应用程序崩溃了吗?网络上是否有拥塞?网络宕机了吗?在某些情况下,应用程序不再运行,您可以简单地忽略该节点并继续您正在做的事情。在其他情况下,应用程序仍在孤立节点上运行;从该节点的角度来看,其他所有东西都死了。
Erlang 做出了默认决策,将不可达节点视为死节点,将可达节点视为活节点。这是一种悲观的做法,如果你想非常快地应对灾难性故障,这很有意义;它假设网络通常比系统中的硬件或软件更容易出现故障,考虑到 Erlang 最初的使用方式,这很有意义。乐观的方法(假设节点仍然存活)可能会延迟与崩溃相关的措施,因为它假设网络比硬件或软件更容易出现故障,从而使集群等待更长时间以重新集成断开的节点。
这提出了一个问题。在悲观的系统中,当我们认为已经死去的节点突然又回来了,结果它根本没有死时会发生什么?我们被一个活着的死节点所震惊,它拥有自己的生命,与集群完全隔离:数据、连接等。会发生一些非常令人讨厌的事情。
让我们想象一下,您有一个系统,在两个不同的数据中心有两个节点。在这个系统中,用户在其帐户中拥有资金,每个节点都持有全部金额。然后每个事务将数据同步到所有其他节点。当所有节点都正常时,用户可以继续花钱,直到他的帐户为空,然后就无法再出售任何东西了。
软件运行良好,但在某些时候,其中一个节点与另一个节点断开连接。无法知道另一方是活着还是死了。就我们所知,这两个节点仍然可以接收来自公众的请求,但无法相互通信。
有两种基本策略可以选择:停止所有交易或不停止。选择第一个的风险是您的产品将变得不可用,您将损失金钱。选择第二个的风险是,一个在账户中有 1000 美元的用户现在有两个服务器可以接受 1000 美元的交易,总计 2000 美元!无论我们做什么,如果我们做错事,我们都有可能损失金钱。
有没有办法通过在网络分裂期间保持应用程序可用,而不必在服务器之间丢失数据来完全避免这个问题?

我的另一个帽子是一个定理
对上一个问题的快速回答是否。可悲的是,在网络分裂期间,没有办法同时保持应用程序的活动和正确性。
这个想法被称为CAP 定理(您可能也对您无法牺牲分区容忍性感兴趣)。CAP 定理首先指出,所有分布式系统都存在三个核心属性:C一致性、A可用性和P分区容忍性。
一致性
在前面的示例中,一致性是指能够让系统(无论有 2 个节点还是 1000 个节点可以回答查询)在给定时间看到帐户中完全相同的金额。这通常通过添加事务(所有节点必须在执行更改之前同意对数据库进行更改作为单个单元)或其他等效机制来完成。
根据定义,一致性的概念是所有操作看起来都像是在跨多个节点完成的单个不可分割的块一样完成的。这与时间无关,而是指在对同一数据段进行操作时,不会出现两个不同的操作以导致系统在这些操作期间报告多个不同的值。应该能够修改数据段,而不必担心其他参与者在您修改数据的同时也会修改数据,从而破坏您的工作。
可用性
可用性的概念是,如果您向系统请求某些数据,您能够收到响应。如果您没有收到答案,那么系统对您不可用。请注意,一个说“对不起,我无法弄清楚结果,因为我已经死了”的响应并不是真正的响应,而只是它的一个悲哀的借口。此响应与没有响应一样没有更多有用的信息(尽管学术界对此问题存在一些分歧)。
注意:CAP 定理中一个重要的考虑因素是,可用性只对未死的节点有影响。死节点无法发送响应,因为它首先无法接收查询。这与节点无法发送回复不同,因为其依赖的事物不再存在!如果节点无法接受请求、更改数据或返回错误结果,从技术上讲它不会对系统正确性的平衡构成威胁。集群的其余部分只需要处理更多负载,直到它恢复并可以同步。
分区容忍性
这是 CAP 定理的棘手部分。分区容忍性通常意味着即使系统的一部分无法相互通信,系统也可以继续工作(并包含有用的信息)。分区容忍性的要点是系统可以在消息可能在组件之间丢失的情况下工作。定义有点抽象和开放式,我们将看到原因。
CAP 定理基本上规定,在任何分布式系统中,您只能拥有 CAP 中的两个:CA、CP 或 AP。不可能同时拥有所有三个。这既是坏消息,也是好消息。坏消息是,即使在网络出现故障的情况下,也无法保证一切都能正常进行。好消息是,这是一个定理。如果客户要求您提供所有三个,您将有优势告诉他们这实际上是不可能的,并且不必在解释 CAP 定理是什么之外花费太多时间。
在这三种可能性中,我们可以通常忽略的一种是 CA(一致性和可用性)的想法。这样做的原因是,您真正想要这种情况的唯一时间是,如果您敢于说网络永远不会出现故障,或者如果出现故障,它会作为原子单位出现(如果一个东西出现故障,那么所有东西都会同时出现故障)。
在有人发明了永不出现故障的网络和硬件,或有某种方法可以在一个部分出现故障时使系统的所有部分同时出现故障之前,故障将成为一种选择。CAP 定理只剩下两种组合:AP 或 CP。被网络分裂撕裂的系统可以保持可用或一致,但不能同时保持两者。
注意:某些系统会选择既没有“A”也没有“C”。在某些高性能的情况下,吞吐量(可以回答的所有查询数量)或延迟(可以回答查询的速度)等标准将以一种方式弯曲事物,使得 CAP 定理不仅仅是关于 2 个属性(CA、CP 或 AP),还与 2 个或更少的属性有关。
对于我们的幸存者小组来说,时间过去了,他们抵挡住了好几群不死者的攻击。子弹穿透了大脑,棒球棒击碎了头骨,被咬的人被留在了后面。比尔、佐伊、瑞克和达里尔的电池最终耗尽了,他们无法交流。幸运的是,他们都找到了两个幸存者殖民地,那里住着热衷于僵尸生存的计算机科学家和工程师。殖民地幸存者习惯了分布式编程的概念,并且习惯了使用自制协议通过光信号和镜子进行交流。
比尔和佐伊找到了“电锯”殖民地,而瑞克和达里尔找到了“弩”营地。鉴于我们的幸存者是他们各自殖民地中最新的成员,他们经常被委派到野外,寻找食物和杀死离外围太近的僵尸,而其他人则争论 vim 和 emacs 的优缺点,这是在完全的僵尸末日之后无法消失的唯一战争。
在他们在那里的第 100 天,我们的四位幸存者被派去到两个营地之间的中点进行商品交易。
在离开之前,电锯和弩殖民地决定了一个会合点。如果在任何时候目标地点或会面时间要更改,瑞克和达里尔可以给弩殖民地发消息,佐伊和比尔可以给电锯殖民地发消息。然后每个殖民地将信息传达给另一个殖民地,另一个殖民地将更改转发给其他幸存者
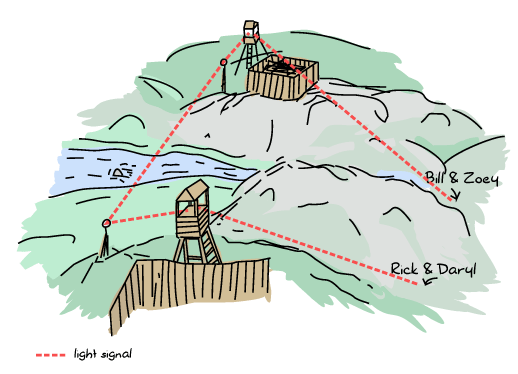
因此,考虑到这一点,所有四位幸存者都在周日清晨早早出发,开始了长途步行,计划在周五黎明前会面。一切都进展顺利(除了偶尔与已经活了很长时间的死人发生冲突)。
不幸的是,在周三,强降雨和增加的僵尸活动导致比尔和佐伊分离、迷路和延迟。新情况看起来有点像这样
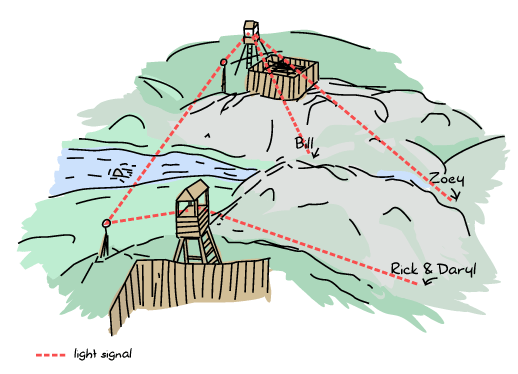
更糟糕的是,雨后,两个殖民地之间通常晴朗的天空变得雾蒙蒙,电锯计算机科学家无法与弩人进行交流。
比尔和佐伊将他们的问题告知了他们的殖民地,并要求设定新的会面时间。如果没有雾,这将是可以的,但现在我们遇到了相当于网络分裂的情况。
如果两个营地都采用一致性 + 分区容错(CP)方法,他们只会阻止 Zoey 和 Bill 设置新的会议时间。看,CP 方法通常是关于阻止对数据的修改,以便保持一致性,并且所有幸存者仍然可以不时向他们各自的营地询问日期。他们只是会被拒绝更改日期的权利。这样做将确保不会出现某些幸存者破坏计划的会议时间的情况——任何其他与任何联系断开的幸存者都可以按计划时间到达那里,无论发生什么,都是独立的。
如果两个营地选择可用性 + 分区容错(AP)方法,那么幸存者就可以被允许更改会议日期。分区双方的每个部分都将拥有会议数据的独立版本。因此,如果 Bill 要求在周五晚上召开新的会议,那么总体状态就会变成:
Chainsaw: Friday night Crossbow: Friday before dawn
只要分裂持续存在,Bill 和 Zoey 将从 Chainsaw 获取信息,Rick 和 Daryl 将从 Crossbow 获取信息。这使得部分幸存者能够在需要时重新组织自己。
这里有趣的问题是如何处理在分裂解决(雾消失)时不同版本的数据。CP 方法对此非常直接:数据没有改变,无需操作。AP 方法有更大的灵活性,但也需要解决更多问题。通常,会采用不同的策略:
- 最后写入获胜是一种冲突解决方法,其中保留最后一次更新。这可能会很棘手,因为在分布式环境中,时间戳可能会出错,或者事情可能在完全相同的时间发生。
- 可以随机选择一个获胜者。
- 更复杂的方法有助于减少冲突,包括基于时间的类似最后写入获胜方法,但使用相对时钟。相对时钟不使用绝对时间值,而是使用每次有人修改文件时递增的值。如果您想了解更多关于此的信息,请阅读有关Lamport 时钟或向量时钟的内容。
- 处理冲突的选择权可以推回到应用程序(或者在我们的案例中,推回到幸存者)。接收端只需选择冲突的条目中的哪一个是正确的即可。这有点类似于您在使用 SVN、Mercurial、Git 等源代码控制时遇到合并冲突的情况。
哪个更好?我描述事物的方式让我们认为我们可以选择完全 AP 或完全 CP,就像一个开关一样。在现实世界中,我们可以使用各种东西,比如仲裁系统,我们可以将这个问题变成一个拨盘,我们可以通过它来选择我们想要的一致性程度。
仲裁系统通过几个非常简单的规则运作。您在系统中拥有 N 个节点,并且需要 M 个节点同意修改数据才能使其生效。一个一致性要求相对较低的系统可能只要求 15% 的节点可用才能进行更改。这意味着,在发生分裂的情况下,即使是网络的小部分碎片也可以继续修改数据。一个更高的 一致性等级,设置为可能 75% 的节点,意味着需要系统中更大的部分存在才能进行更改。在这种情况下,如果几个节点被隔离,它们将没有更改数据的权利。然而,系统中仍然相互连接的主要部分可以正常工作。
通过更改 M 值,使必需节点的值达到 N(节点总数),您可以获得一个完全一致的系统。通过将 M 的值设置为 1,您将获得一个完全 AP 的系统,没有一致性保证。
此外,您可以在每个查询的基础上玩转这些值:与不太重要的事情有关的查询(有人刚刚登录!)可以具有较低的一致性要求,而与库存和金钱有关的事情可能需要更高的 一致性。将此与每种情况的不同冲突解决方法相结合,您就可以获得令人惊讶的灵活系统。
结合所有可用的冲突解决方案,分布式系统可以获得很多选项,但它们的实现仍然非常复杂。我们不会详细介绍它们,但我认为了解这些选项的存在很重要,以便了解可用的不同选项。
现在,我们可以坚持使用 Erlang 进行分布式计算的基本知识。
设置 Erlang 集群
除了处理分布式计算谬误的整个部分之外,分布式 Erlang 最难的部分是首先设法正确设置。在不同的主机之间连接节点是一种特殊的痛苦。为了避免这种情况,我们通常会尝试使用一台计算机上的多个节点进行测试,这往往会使事情变得更容易。
如前所述,Erlang 为每个节点命名,以便能够找到并联系它们。名称格式为 Name@Host,其中主机基于可用的 DNS 条目,这些条目可以通过网络或您计算机的主机文件 (/etc/hosts 在 OSX、Linux 和其他类 Unix 系统上,C:\Windows\system32\drivers\etc\hosts 适用于大多数 Windows 安装) 获得。所有名称都需要是唯一的,以避免冲突——如果您尝试启动一个节点,其名称与同一主机名上的另一个节点相同,您将获得一个非常糟糕的崩溃消息。
在启动这些 shell 以引发崩溃之前,我们必须了解一些关于名称的信息。名称有两种类型:短名称和长名称。长名称基于完全限定的域名 (aaa.bbb.ccc),并且许多 DNS 解析器认为域名如果包含一个句点 (.),则为完全限定的。短名称将基于没有句点的主机名,并通过您的主机文件或任何可能的 DNS 条目进行解析。因此,一般来说,使用短名称在同一台计算机上设置多个 Erlang 节点比使用长名称更容易。还有一点:由于名称需要是唯一的,因此使用短名称的节点无法与使用长名称的节点通信,反之亦然。
要选择长名称或短名称,您可以使用两种不同的选项启动 Erlang 虚拟机:erl -sname short_name@domain 或 erl -name long_name@some.domain。请注意,您也可以只使用名称启动节点:erl -sname short_name 或 erl -name long_name。Erlang 会自动根据您的操作系统的配置分配一个主机名。最后,您还可以选择使用类似 erl -name name@127.0.0.1 的名称启动节点,以提供直接的 IP 地址。
注意:Windows 用户仍然应该使用 werl 而不是 erl。但是,为了启动分布式节点并为其命名,应从命令行启动节点,而不是单击某个快捷方式或可执行文件。
让我们启动两个节点:
erl -sname ketchup ... (ketchup@ferdmbp)1>
erl -sname fries ... (fries@ferdmbp)1>
要将薯条与番茄酱连接起来(并创建一个美味的集群),请转到第一个 shell 并输入以下函数:
(ketchup@ferdmbp)1> net_kernel:connect_node(fries@ferdmbp). true
net_kernel:connect_node(NodeName) 函数与另一个 Erlang 节点建立连接(一些教程使用 net_adm:ping(Node),但我认为 net_kernel:connect_node/1 听起来更严肃,并且更能让我相信!)。如果您看到函数调用的结果是 true,恭喜您,您现在处于分布式 Erlang 模式。如果您看到 false,那么您将陷入困境,试图让您的网络正常运行。对于非常快速的解决方法,请编辑您的主机文件以接受您想要的任何主机。再次尝试,看看是否有效。
您可以通过调用 BIF node() 来查看您自己的节点名称,并通过调用 BIF nodes() 来查看您正在连接的人。
(ketchup@ferdmbp)2> node(). ketchup@ferdmbp (ketchup@ferdmbp)3> nodes(). [fries@ferdmbp]
为了让节点相互通信,我们将尝试使用一个非常简单的技巧。将每个 shell 的进程在本地注册为 shell。
(ketchup@ferdmbp)4> register(shell, self()). true
(fries@ferdmbp)1> register(shell, self()). true
然后,您就可以通过名称调用进程。这样做的方法是向 {Name, Node} 发送消息。让我们在两个 shell 上尝试一下:
(ketchup@ferdmbp)5> {shell, fries@ferdmbp} ! {hello, from, self()}.
{hello,from,<0.52.0>}
(fries@ferdmbp)2> receive {hello, from, OtherShell} -> OtherShell ! <<"hey there!">> end.
<<"hey there!">>
因此,消息显然已收到,我们向另一个 shell 发送了一些内容,它也收到了消息:
(ketchup@ferdmbp)6> flush(). Shell got <<"hey there!">> ok
如您所见,我们可以透明地发送元组、原子、pid 和二进制文件,而不会出现任何问题。任何其他 Erlang 数据结构也都可以。就是这样。您知道如何使用分布式 Erlang!还有一个可能很有用的 BIF:erlang:monitor_node(NodeName, Bool)。如果节点死亡,此函数将允许调用它的进程(使用 true 作为 Bool 的值)接收格式为 {nodedown, NodeName} 的消息。
除非您正在编写一个依赖于检查其他节点生命周期的特殊库,否则您很少需要使用 erlang:monitor_node/2。原因是 link/1 和 monitor/2 等函数仍然可以在节点之间工作。
如果您从 fries 节点设置了以下内容:
(fries@ferdmbp)3> process_flag(trap_exit, true). false (fries@ferdmbp)4> link(OtherShell). true (fries@ferdmbp)5> erlang:monitor(process, OtherShell). #Ref<0.0.0.132>
然后杀死 ketchup 节点,fries 的 shell 进程应该接收一个 'EXIT' 和监视消息:
(fries@ferdmbp)6> flush().
Shell got {'DOWN',#Ref<0.0.0.132>,process,<6349.52.0>,noconnection}
Shell got {'EXIT',<6349.52.0>,noconnection}
ok
这就是您会看到的内容。但是,等等。为什么 pid 看起来是这样的?我是不是看错了?
(fries@ferdmbp)7> OtherShell. <6349.52.0>
什么?这不是应该是 <0.52.0> 吗?不。看,这种显示 pid 的方式只是对进程标识符的真实表示的一种视觉表示。第一个数字表示节点(其中 0 表示进程来自当前节点),第二个数字是一个计数器,第三个数字是在创建了太多进程,第一个计数器不够用时使用的另一个计数器。pid 的真实底层表示更像是这样:
(fries@ferdmbp)8> term_to_binary(OtherShell). <<131,103,100,0,15,107,101,116,99,104,117,112,64,102,101, 114,100,109,98,112,0,0,0,52,0,0,0,0,3>>
二进制序列 <<107,101,116,99,104,117,112,64,102,101,114,100,109,98,112>> 事实上是 <<"ketchup@ferdmbp">> 的拉丁 1(或 ASCII)表示,它是进程所在节点的名称。然后是两个计数器:<<0,0,0,52>> 和 <<0,0,0,0>>。最后一个值 (3) 是一个令牌值,用于区分 pid 是来自旧节点、已死节点等。这就是为什么 pid 可以透明地在任何地方使用的原因。
注意:除了杀死节点以断开连接之外,您还可以尝试使用 BIF erlang:disconnect_node(Node) 来摆脱节点,而不会将其关闭。
注意:如果您不确定 Pid 来自哪个节点,则无需将其转换为二进制文件以读取节点名称。只需调用 node(Pid),它运行所在的节点将以字符串形式返回。
其他有趣的 BIF 是 spawn/2、spawn/4、spawn_link/2 和 spawn_link/4。它们的工作原理与其他 spawn BIF 完全相同,只是这些 BIF 允许您在远程节点上生成函数。从 ketchup 节点尝试一下:
(ketchup@ferdmbp)6> spawn(fries@ferdmbp, fun() -> io:format("I'm on ~p~n", [node()]) end).
I'm on fries@ferdmbp
<6448.50.0>
这本质上是一个远程过程调用:我们可以选择在其他节点上运行任意代码,而无需给自己带来更多麻烦!有趣的是,该函数是在另一个节点上运行的,但我们是在本地接收输出。没错,即使是输出也可以透明地通过网络重定向。这样做的原因是基于组领导者这个概念。组领导者无论是在本地还是远程,都是以相同的方式继承的。
这些就是您在 Erlang 中编写分布式代码所需的所有工具。您刚获得了您的开山刀、手电筒和胡子。您所处的水平是用其他没有这种分布层的语言需要很长时间才能达到的。现在是时候杀死怪物了。或者也许首先,我们必须了解一下饼干怪兽。
饼干

如果你还记得本章开头,我提到了所有 Erlang 节点都被设置为网状结构的想法。如果有人连接到一个节点,它会连接到所有其他节点。有时你想要做的事情是在同一台硬件上运行不同的 Erlang 节点集群。在这些情况下,你不想意外地将两个 Erlang 节点集群连接在一起。
因此,Erlang 的设计者添加了一个名为 cookie 的小令牌值。虽然像官方 Erlang 文档这样的文档将 cookie 列为安全主题,但它们实际上并不安全。如果它是一种安全措施,那只能算是一种笑话,因为没有人会认真地认为 cookie 是安全的。为什么?简单地说,因为 cookie 是一个小的唯一值,必须在节点之间共享才能使它们连接在一起。它们更像是用户名而不是密码,我敢肯定没有人会认为使用用户名(而不是其他任何东西)是一种安全功能。cookie 更像是用于划分节点集群的机制,而不是身份验证机制。
要向节点提供 cookie,只需通过在命令行中添加 -setcookie Cookie 参数来启动它。让我们尝试使用两个新节点再次尝试
$ erl -sname salad -setcookie 'myvoiceismypassword' ... (salad@ferdmbp)1>
$ erl -sname mustard -setcookie 'opensesame' ... (mustard@ferdmbp)1>
现在这两个节点都有不同的 cookie,它们不应该能够相互通信
(salad@ferdmbp)1> net_kernel:connect_node(mustard@ferdmbp). false
这个请求被拒绝了。没有太多解释。但是,如果我们查看 mustard 节点
=ERROR REPORT==== 10-Dec-2011::13:39:27 === ** Connection attempt from disallowed node salad@ferdmbp **
很好。现在如果我们真的想让 salad 和 mustard 联系在一起呢?有一个名为 erlang:set_cookie/2 的 BIF 可以做到我们需要的。如果你调用 erlang:set_cookie(OtherNode, Cookie),你将仅在连接到该其他节点时使用该 cookie。如果你改为使用 erlang:set_cookie(node(), Cookie),你将更改节点的当前 cookie 以用于所有将来的连接。要查看更改,请使用 erlang:get_cookie()
(salad@ferdmbp)2> erlang:get_cookie(). myvoiceismypassword (salad@ferdmbp)3> erlang:set_cookie(mustard@ferdmbp, opensesame). true (salad@ferdmbp)4> erlang:get_cookie(). myvoiceismypassword (salad@ferdmbp)5> net_kernel:connect_node(mustard@ferdmbp). true (salad@ferdmbp)6> erlang:set_cookie(node(), now_it_changes). true (salad@ferdmbp)7> erlang:get_cookie(). now_it_changes
太棒了。还有一个 cookie 机制需要看看。如果你尝试了本章前面的示例,请查看你的主目录。那里应该有一个名为 .erlang.cookie 的文件。如果你读取它,你会看到一个随机字符串,看起来有点像 PMIYERCHJZNZGSRJPVRK。每当你启动一个没有特定命令来提供 cookie 的分布式节点时,Erlang 会创建一个并将其放入该文件。然后,每次你再次启动一个节点而没有指定其 cookie 时,VM 会查看你的主目录并使用该文件中的任何内容。
远程 Shell
我们在 Erlang 中学习的第一件事是如何使用 ^G (CTRL + G) 中断正在运行的代码。在那里,我们看到了一个用于分布式 shell 的菜单
(salad@ferdmbp)1> User switch command --> h c [nn] - connect to job i [nn] - interrupt job k [nn] - kill job j - list all jobs s [shell] - start local shell r [node [shell]] - start remote shell q - quit erlang ? | h - this message
r [node [shell]] 选项是我们正在寻找的选项。我们可以通过以下步骤在 mustard 节点上启动一个作业
--> r mustard@ferdmbp
--> j
1 {shell,start,[init]}
2* {mustard@ferdmbp,shell,start,[]}
--> c
Eshell V5.8.4 (abort with ^G)
(mustard@ferdmbp)1> node().
mustard@ferdmbp
就是这样。你现在可以使用远程 shell,就像使用本地 shell 一样。与旧版本的 Erlang 相比,有一些不同之处,例如自动完成功能不再起作用。无论何时你需要更改使用 -noshell 选项运行的节点上的内容,这种方法仍然非常有用。如果 -noshell 节点有名称,那么你可以连接到它来执行与管理相关的操作,例如重新加载模块、调试一些代码等等。
通过再次使用 ^G,你可以返回到你的原始节点。但是,在停止会话时要小心。如果你调用 q() 或 init:stop(),你将终止远程节点!

隐藏节点
Erlang 节点可以通过调用 net_kernel:connect_node/1 连接,但你必须知道,节点之间的几乎任何交互都会使它们建立连接。调用 spawn/2 或向外部 Pid 发送消息会自动建立连接。
如果你有一个相当大的集群,并且想要连接到单个节点以更改一些内容,这可能会很烦人。你不希望你的管理节点突然被集成到集群中,并且让其他节点认为它们有一个新的同事可以发送任务。为此,你可以使用很少使用的 erlang:send(Dest, Message, [noconnect]) 函数,该函数会在不创建连接的情况下发送消息,但这很容易出错。
相反,你想要做的是使用 -hidden 标志设置一个节点。假设你仍然运行着 mustard 和 salad 节点。我们将启动第三个节点 olives,它将仅连接到 mustard(确保 cookie 相同!)
$ erl -sname olives -hidden ... (olives@ferdmbp)1> net_kernel:connect_node(mustard@ferdmbp). true (olives@ferdmbp)2> nodes(). [] (olives@ferdmbp)3> nodes(hidden). [mustard@ferdmbp]
啊哈!该节点没有连接到 salad,并且乍一看,它也没有连接到 mustard。但是,调用 node(hidden) 显示我们确实在那里有一个连接!让我们看看 mustard 节点看到了什么
(mustard@ferdmbp)1> nodes(). [salad@ferdmbp] (mustard@ferdmbp)2> nodes(hidden). [olives@ferdmbp] (mustard@ferdmbp)3> nodes(connected). [salad@ferdmbp,olives@ferdmbp]
类似的视图,但现在我们添加了 nodes(connected) BIF,它显示所有连接,无论它们的类型如何。salad 节点永远不会看到与 olives 的任何连接,除非特别指示它在那里连接。nodes/1 的最后一个有趣的用法是使用 nodes(known),它将显示当前节点曾经连接到的所有节点。
使用远程 shell、cookie 和隐藏节点,管理分布式 Erlang 系统变得更加简单。
墙是用火做的,护目镜毫无用处
如果你发现自己想通过防火墙使用分布式 Erlang(并且不想使用隧道),你可能需要为 Erlang 通信打开一些端口。如果你想这样做,你需要打开端口 4369,这是 EPMD 的默认端口。使用这个端口是一个好主意,因为它由爱立信正式注册用于 EPMD。这意味着你使用的任何符合标准的操作系统都将拥有该端口,并且该端口将处于空闲状态,准备用于 EPMD。
然后,你需要打开一组端口以用于节点之间的连接。问题是 Erlang 只会为节点间连接分配随机端口号。但是,有两个隐藏的应用程序变量可以让你指定可以分配端口的范围。这两个值分别是 kernel 应用程序中的 inet_dist_listen_min 和 inet_dist_listen_max。
例如,你可以以 erl -name left_4_distribudead -kernel inet_dist_listen_min 9100 -kernel inet_dist_listen_max 9115 的方式启动 Erlang,以便设置一个范围为 16 个端口的范围,供 Erlang 节点使用。或者,你可以使用一个看起来像这样的配置文件 ports.config
[{kernel,[
{inet_dist_listen_min, 9100},
{inet_dist_listen_max, 9115}
]}].
然后以 erl -name the_army_of_darknodes -config ports 的方式启动 Erlang 节点。这些变量将以相同的方式设置。
来自彼岸的呼唤
除了我们已经看到的所有 BIF 和概念之外,还有一些模块可以帮助开发人员使用分布式。第一个是 net_kernel,我们使用它来连接节点,并且如前所述,它可以用来断开连接。
它还有一些其他高级功能,例如能够将非分布式节点转换为分布式节点
erl
...
1> net_kernel:start([romero, shortnames]).
{ok,<0.43.0>}
(romero@ferdmbp)2>
你可以在其中使用 shortnames 或 longnames 来定义是否要具有 -sname 或 -name 的等效项。此外,如果你知道一个节点将发送大型消息,因此可能需要节点之间较大的心跳时间,则可以将第三个参数传递给列表。这将给出 net_kernel:start([Name, Type, HeartbeatInMilliseconds])。默认情况下,心跳延迟设置为 15 秒或 15,000 毫秒。在 4 次心跳失败后,远程节点将被视为已死。心跳延迟乘以 4 称为 滴答时间。
该模块的其他函数包括 net_kernel:set_net_ticktime(S),它允许你更改节点的滴答时间以避免断开连接(其中 S 是秒数,因为它是滴答时间,它必须是心跳延迟的 4 倍!),以及 net_kernel:stop() 来停止分布并返回到正常的节点
(romero@ferdmbp)2> net_kernel:set_net_ticktime(5). change_initiated (romero@ferdmbp)3> net_kernel:stop(). ok 4>
下一个用于分布的有用模块是 global。global 模块是一个新的替代进程注册表。它会自动将数据传播到所有连接的节点,在这些节点中复制数据,处理节点故障,并在节点重新上线后支持不同的冲突解决策略。
你可以通过调用 global:register_name(Name, Pid) 注册名称,通过 global:unregister_name(Name) 注销。如果你想要进行名称转移而从未让它指向空,你可以调用 global:re_register_name(Name, Pid)。你可以使用 global:whereis_name(Name) 查找进程的 ID,并通过调用 global:send(Name, Message) 向其中发送消息。你需要的功能应有尽有。特别棒的是,你用来注册进程的名称可以是任何项。
当两个节点连接在一起并且它们都具有两个共享相同名称的不同进程时,会发生命名冲突。在这些情况下,global 会默认随机杀死其中一个。有一些方法可以覆盖这种行为。每当你注册或重新注册一个名称时,向函数传递第三个参数
5> Resolve = fun(_Name,Pid1,Pid2) ->
5> case process_info(Pid1, message_queue_len) > process_info(Pid2, message_queue_len) of
5> true -> Pid1;
5> false -> Pid2
5> end
5> end.
#Fun<erl_eval.18.59269574>
6> global:register_name({zombie, 12}, self(), Resolve).
yes
Resolve 函数将选择邮箱中消息最多的进程作为要保留的进程(它也是函数返回的进程的 pid)。或者,你可以联系这两个进程并询问谁的订阅者最多,或者只保留第一个回复的进程,等等。如果 Resolve 函数崩溃或返回的不是 pid,则进程名称将被注销。为了方便起见,global 模块已经为你定义了三个函数
fun global:random_exit_name/3将随机杀死一个进程。这是默认选项。fun global:random_notify_name/3将随机选择两个进程中的一个作为幸存者,它会将{global_name_conflict, Name}发送给失败的进程。fun global:notify_all_name/3它会注销两个 pid,并将消息{global_name_conflict, Name, OtherPid}发送给这两个进程,让它们自己解决问题,以便再次重新注册。

global 模块有一个缺点,通常说的是它在检测名称冲突和节点下降方面速度很慢。否则它是一个很好的模块,甚至被行为支持。只需更改所有使用本地名称({local, Name})的 gen_Something:start_link(...) 调用,改为使用 {global, Name},然后将所有调用和投递(及其等效项)改为使用 {global, Name},而不是仅使用 Name,这样就会分布式。
列表中的下一个模块是 rpc,它代表远程过程调用。它包含允许你执行远程节点上的命令的函数,以及一些用于促进并行操作的函数。为了测试这些,让我们从启动两个不同的节点并将它们连接在一起开始。这次我不会展示这些步骤,因为我认为你现在已经了解了它的工作原理。这两个节点将是 cthulu 和 lovecraft。
最基本的 rpc 操作是 rpc:call/4-5。它允许你在远程节点上运行给定的操作并在本地获取结果
(cthulu@ferdmbp)1> rpc:call(lovecraft@ferdmbp, lists, sort, [[a,e,f,t,h,s,a]]).
[a,a,e,f,h,s,t]
(cthulu@ferdmbp)2> rpc:call(lovecraft@ferdmbp, timer, sleep, [10000], 500).
{badrpc,timeout}
如在本 Cthulu 节点中所见,该函数具有四个参数,其形式为 rpc:call(Node, Module, Function, Args)。添加第五个参数将提供超时时间。rpc 调用将返回其运行的函数返回的任何内容,或者在发生故障的情况下返回 {badrpc, Reason}。
如果您之前学习过一些分布式或并行计算的概念,您可能听说过 Promise。Promise 有点像远程过程调用,只是它们是异步的。rpc 模块允许我们拥有这种功能
(cthulu@ferdmbp)3> Key = rpc:async_call(lovecraft@ferdmbp, erlang, node, []). <0.45.0> (cthulu@ferdmbp)4> rpc:yield(Key). lovecraft@ferdmbp
通过将函数 rpc:async_call/4 的结果与函数 rpc:yield(Res) 相结合,我们可以进行异步远程过程调用并稍后获取结果。当您知道要进行的 RPC 需要一段时间才能返回时,这尤其有用。在这种情况下,您将其发送出去,然后忙于做其他事情(其他调用、从数据库中获取记录、喝茶),然后在没有其他事情可做时等待结果。当然,如果您需要,您可以在自己的节点上进行此类调用
(cthulu@ferdmbp)5> MaxTime = rpc:async_call(node(), timer, sleep, [30000]). <0.48.0> (cthulu@ferdmbp)6> lists:sort([a,c,b]). [a,b,c] (cthulu@ferdmbp)7> rpc:yield(MaxTime). ... [long wait] ... ok
如果您碰巧想使用带有超时值的 yield/1 函数,请改用 rpc:nb_yield(Key, Timeout)。要轮询结果,请使用 rpc:nb_yield(Key)(等效于 rpc:nb_yield(Key, 0))
(cthulu@ferdmbp)8> Key2 = rpc:async_call(node(), timer, sleep, [30000]).
<0.52.0>
(cthulu@ferdmbp)9> rpc:nb_yield(Key2).
timeout
(cthulu@ferdmbp)10> rpc:nb_yield(Key2).
timeout
(cthulu@ferdmbp)11> rpc:nb_yield(Key2).
timeout
(cthulu@ferdmbp)12> rpc:nb_yield(Key2, 1000).
timeout
(cthulu@ferdmbp)13> rpc:nb_yield(Key2, 100000).
... [long wait] ...
{value,ok}
如果您不关心结果,那么可以使用 rpc:cast(Node, Mod, Fun, Args) 向另一个节点发送命令并忽略它。
未来是你的了!但是等等,如果我们想要一次调用多个节点呢?让我们将三个节点添加到我们的集群中:minion1、minion2 和 minion3。它们是 Cthulu 的爪牙。当我们想问他们问题时,我们必须发送 3 个不同的调用,当我们想下达命令时,我们必须执行 3 次。这很糟糕,而且它无法随着大型军队的规模而扩展。
诀窍是分别使用两个 RPC 函数来进行调用和广播,分别是 rpc:multicall(Nodes, Mod, Fun, Args)(带有一个可选的 Timeout 参数)和 rpc:eval_everywhere(Nodes, Mod, Fun, Args)
(cthulu@ferdmbp)14> nodes().
[lovecraft@ferdmbp, minion1@ferdmbp, minion2@ferdmbp, minion3@ferdmbp]
(cthulu@ferdmbp)15> rpc:multicall(nodes(), erlang, is_alive, []).
{[true,true,true,true],[]}
这告诉我们所有四个节点都处于活动状态(并且没有人无法回答)。元组的左侧是活动的,右侧不是。是的,erlang:is_alive() 只是返回它运行的节点是否处于活动状态,这可能看起来有点奇怪。再一次,请记住,在分布式环境中,alive 表示“可以到达”,而不是“正在运行”。然后假设 Cthulu 并不真正欣赏它的爪牙,并决定杀死它们,或者更确切地说,说服它们自杀。这是一个命令,因此它是广播的。出于这个原因,我们在 minion 节点上使用 eval_everywhere/4 来调用 init:stop()
(cthulu@ferdmbp)16> rpc:eval_everywhere([minion1@ferdmbp, minion2@ferdmbp, minion3@ferdmbp], init, stop, []).
abcast
(cthulu@ferdmbp)17> rpc:multicall([lovecraft@ferdmbp, minion1@ferdmbp, minion2@ferdmbp, minion3@ferdmbp], erlang, is_alive, []).
{[true],[minion1@ferdmbp, minion2@ferdmbp, minion3@ferdmbp]}
当我们再次询问谁还活着时,只剩下一个节点,即 Lovecraft 节点。爪牙是服从的生物。那里还有几个更有趣的 RPC 函数,但核心用途已在此处介绍。如果您想了解更多信息,我建议您仔细阅读该模块的文档。
埋葬《分布式秘典》
好吧,这就是分布式 Erlang 的大部分基础知识。有很多事情需要考虑,很多属性需要牢记。无论何时您必须开发一个分布式应用程序,都要问问自己您可能会遇到哪些分布式计算谬误(如果有的话)。如果客户要求您构建一个在保持一致性和可用性的同时处理网络分区故障的系统,您就知道您需要平静地解释 CAP 定理或者逃跑(可能要从窗户跳出去,以获得最大的效果)。
通常,在一千个独立的节点可以在没有通信或相互依赖的情况下完成工作的情况下,应用程序将提供最佳的可扩展性。创建的节点间依赖性越多,扩展难度就越大,无论您使用哪种分布式层。这就像僵尸(不,真的!)。僵尸之所以可怕是因为它们的數量很多,而且作为群体,它们难以杀死。即使单个僵尸可能非常缓慢,而且远非具有威胁性,但一大群僵尸可以造成相当大的破坏,即使它失去了许多僵尸成员。人类幸存者群体可以通过结合他们的智慧和相互沟通来完成伟大的事情,但他们遭受的每一次损失都会对该群体及其生存能力造成更大的负担。
话虽如此,您已经拥有了开始行动所需的工具。下一章将介绍分布式 OTP 应用程序的概念——它为硬件故障提供了接管和故障转移机制,但不是一般的分布式;它更像是让你的死去的僵尸重生,而不是其他任何东西。