熊,ETS,甜菜

我们一直在做的一件事就是将某种存储设备实现为一个进程。我们已经做过冰箱来存放东西,构建了 regis 来注册进程,看到了键值存储等等。如果我们是做面向对象设计的程序员,我们就会有一堆单例在四处游荡,还有特殊的存储类等等。实际上,将数据结构(如 dict 和 gb_trees)封装在进程中有点像这样。
在很多情况下,在进程中保存数据结构实际上是可以的——无论何时我们真正需要该数据来完成进程中的某些任务,作为内部状态等等。我们有很多有效的用例,我们不应该改变这一点。但是,有一种情况可能不是最佳选择:当进程保存数据结构是为了与其他进程共享,而没有更多目的时。
我们编写的一个应用程序就犯了这个错误。你能猜到是哪个吗?当然可以;我在上一章的最后提到了它:regis 需要重写。不是因为它不工作或不能很好地完成它的工作,而是因为它充当了与可能很多其他进程共享数据的网关,这在架构上存在问题。
看,regis 是一个用来在 Process Quest(以及任何使用它的其他应用程序)中进行消息传递的中心应用程序,几乎所有发送到命名进程的消息都必须经过它。这意味着,尽管我们非常小心地使我们的应用程序通过独立的参与者非常并发,并确保我们的监督结构能够扩展,但我们所有的操作都将依赖于一个中心 regis 进程,该进程需要逐个地回答消息。
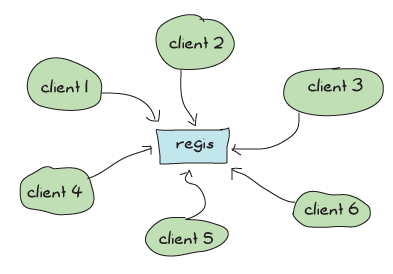
如果我们有很多消息传递发生,regis 可能会变得越来越忙,如果需求足够高,我们的整个系统将变得顺序化并变慢。这很糟糕。
注意: 我们没有直接证据表明 regis 是 Process Quest 中的瓶颈——事实上,与野外许多其他应用程序相比,Process Quest 的消息传递非常少。如果我们使用 regis 来完成需要更多消息传递和查找的任务,那么问题会更加明显。
我们必须解决这个问题的几种方法是:要么将 regis 分割成子进程,通过对数据进行分片来加快查找速度,要么找到一种方法将数据存储在某种数据库中,该数据库允许对数据进行并行和并发访问。虽然第一种方法非常有趣,值得探索,但我们将通过第二种方法走一条更简单的路径。
Erlang 有一个叫做 ETS(Erlang Term Storage)的表。ETS 表是一个高效的内存数据库,包含在 Erlang 虚拟机中。它位于虚拟机的部分,允许破坏性更新,并且垃圾回收不敢靠近它。它们通常很快,对于 Erlang 程序员来说,当他们代码的某些部分运行过慢时,这是一个非常容易的方法来优化代码。
ETS 表允许在读取和写入方面进行有限的并发(比进程的邮箱完全没有并发要好得多),这让我们能够优化掉很多痛苦。
不要喝太多酷乐 aid
虽然 ETS 表是一个不错的优化方法,但仍然应该谨慎使用。默认情况下,VM 限制为 1400 个 ETS 表。虽然可以更改该数字(erl -env ERL_MAX_ETS_TABLES Number),但默认的低级别是一个很好的迹象,表明您应该尽量避免一般情况下每个进程使用一个表。
但在我们重写 regis 以使用 ETS 之前,我们应该先了解一些 ETS 的原理。
ETS 的概念
ETS 表在 ets 模块中实现为 BIF。ETS 的主要设计目标是提供一种方法,在 Erlang 中存储大量数据,并具有恒定访问时间(函数式数据结构通常倾向于与对数访问时间调情),并且使这种存储看起来像是用进程实现的,以便保持其使用简单和惯用。
注意: 让表看起来像进程并不意味着你可以生成它们或链接它们,而是它们可以尊重无共享语义,将调用封装在函数式接口后面,让它们处理 Erlang 的任何本机数据类型,以及能够为它们命名(在单独的注册表中)等等。
所有 ETS 表都以原生方式存储 Erlang 元组,其中包含你想要的任何内容,其中元组的某个元素将充当用来对事物进行排序的主键。也就是说,使用形式为 {Name, Age, PhoneNumber, Email} 的人的元组将让你拥有一个看起来像这样的表
{Name, Age, PhoneNumber, Email},
{Name, Age, PhoneNumber, Email},
{Name, Age, PhoneNumber, Email},
{Name, Age, PhoneNumber, Email},
{Name, Age, PhoneNumber, Email},
...
所以,如果我们说我们想让表的索引是电子邮件地址,我们可以通过告诉 ETS 将键位置设置为 4 来做到这一点(我们将在稍后看到如何做到这一点,当我们开始实际的 ETS 函数调用时)。一旦你决定了键,你可以选择不同的方式将数据存储到表中。
- 集
- 一个集合表将告诉你,每个键实例都必须是唯一的。在上面的数据库中不能有重复的电子邮件。当您需要使用标准的键值存储并具有恒定时间访问时,集合非常有用。
- 有序集
- 每个表中仍然只能有一个键实例,但
ordered_set添加了一些其他有趣的属性。第一个是ordered_set表中的元素将被排序(谁会想到?!)。表中的第一个元素是最小的,最后一个元素是最大的。如果您以迭代方式遍历表(一次又一次地跳到下一个元素),则这些值应该是递增的,而这在set表中并不一定如此。当您经常需要对范围进行操作时,有序集合表非常有用(我想要第 12 到 50 个条目!)。但是,它们的缺点是访问时间较慢(O(log N),其中 N 是存储的对象数量)。 - 包
- 一个包表可以包含具有相同键的多个条目,只要元组本身不同。这意味着表可以包含
{key, some, values}和{key, other, values},而不会出现问题,这对于集合来说是不可能的(它们具有相同的键)。但是,你不能在表中包含两次{key, some, values},因为它们将完全相同。 - 重复包
- 这种类型的表与
bag表的工作方式相同,只是它们允许完全相同的元组在同一个表中多次保存。
注意: 有序集合表将把值 1 和 1.0 视为所有操作中的相同。其他表会将它们视为不同。
要学习的最后一个通用概念是,ETS 表将具有控制进程的概念,就像套接字一样。当一个进程调用一个函数来启动一个新的 ETS 表时,该进程就是表的拥有者。
默认情况下,只有表的拥有者可以写入它,但每个人都可以读取它。这被称为保护权限级别。您还可以选择将权限设置为公共,这样每个人都可以读写,或者设置为私有,这样只有拥有者可以读写。

表所有权的概念更进一步。ETS 表与进程紧密相关。如果进程死亡,表也会消失(以及它的所有内容)。但是,表可以被赠送,就像我们对套接字及其控制进程所做的那样,或者可以确定一个继承人,以便如果拥有者进程死亡,表会自动赠送给继承人进程。
ETS 回家电话
要启动一个 ETS 表,必须调用 ets:new/2 函数。该函数接受参数 Name,然后是一个选项列表。作为回报,您将获得一个用于使用表的唯一标识符,类似于进程的 Pid。这些选项可以是以下任何一项
Type = set | ordered_set | bag | duplicate_bag- 设置您想要拥有的表类型,如上一节所述。默认值为
set。 Access = private | protected | public- 让我们根据之前描述的设置表的权限。默认选项是
protected。 named_table- 有趣的是,如果您调用
ets:new(some_name, []),您将启动一个受保护的集合表,没有名称。为了将名称用作联系表的途径(并使其唯一),必须将named_table选项传递给该函数。否则,表的名称将纯粹用于文档目的,并将出现在诸如ets:i()之类的函数中,这些函数打印有关系统中所有 ETS 表的信息。 {keypos, Position}- 如您可能(应该)记得,ETS 表通过存储元组来工作。参数 Position 持有一个从 1 到 N 的整数,告诉每个元组的哪个元素将作为数据库表的主键。默认键位置设置为 1。这意味着,如果您使用记录,则必须小心,因为每个记录的第一个元素始终是记录的名称(记住它们在元组形式中的样子)。如果您想使用任何字段作为键,请使用
{keypos, #RecordName.FieldName},因为它将返回记录的元组表示中 FieldName 的位置。 {heir, Pid, Data} | {heir, none}- 如上一节所述,ETS 表有一个充当其父进程的进程。如果进程死亡,表也会消失。如果与表关联的数据是您可能希望保持活动的数据,那么定义继承人可能很有用。如果与表关联的进程死亡,继承人会收到一个消息,内容为
{'ETS-TRANSFER', TableId, FromPid, Data}',其中 Data 是在最初定义选项时传递的元素。表会自动被继承人继承。默认情况下,没有定义继承人。可以在以后的时间点通过调用ets:setopts(Table, {heir, Pid, Data})或ets:setopts(Table, {heir, none})来定义或更改继承人。如果您只是想赠送该表,请调用ets:give_away/3。 {read_concurrency, true | false}- 这是一个选项,可以针对读取并发性优化表。将此选项设置为 true 意味着读取变得更便宜,但随后切换到写入会变得更昂贵。基本上,当您进行大量读取和少量写入并需要额外的性能提升时,应该启用此选项。如果您进行一些读取、一些写入,并且它们是交错的,则使用此选项甚至可能会降低性能。
{write_concurrency, true | false}- 通常,写入表会锁定整个表,直到写入完成,任何人都无法访问它,无论是读取还是写入。将此选项设置为 'true' 允许读取和写入同时进行,而不会影响 ETS 的 ACID 属性。但是,这样做会降低单个进程的顺序写入的性能,以及并发读取的容量。当写入和读取都以大量突发形式出现时,您可以将此选项与 'read_concurrency' 组合使用。
压缩- 使用此选项将允许对表中的大多数字段进行压缩,但不会压缩主键。这会影响检查表中整个元素的性能,正如我们将在后面的函数中看到的那样。
然后,与创建表相反的是销毁表。为此,只需调用 ets:delete(Table),其中 Table 是表 ID 或命名表的名称。如果要从表中删除单个条目,则需要非常类似的函数调用:ets:delete(Table, Key)。
还需要两个函数来进行最基本的表处理:insert(Table, ObjectOrObjects) 和 lookup(Table, Key)。在 insert/2 的情况下,ObjectOrObjects 可以是单个元组或要插入的元组列表。
1> ets:new(ingredients, [set, named_table]).
ingredients
2> ets:insert(ingredients, {bacon, great}).
true
3> ets:lookup(ingredients, bacon).
[{bacon,great}]
4> ets:insert(ingredients, [{bacon, awesome}, {cabbage, alright}]).
true
5> ets:lookup(ingredients, bacon).
[{bacon,awesome}]
6> ets:lookup(ingredients, cabbage).
[{cabbage,alright}]
7> ets:delete(ingredients, cabbage).
true
8> ets:lookup(ingredients, cabbage).
[]
您会注意到 lookup 函数返回一个列表。它会对所有类型的表执行此操作,即使基于集合的表总是最多返回一项。这仅仅意味着即使使用包或重复包(对于单个键可能返回多个值),您也能够以通用方式使用 lookup 函数。
上面的代码片段中还发生的一件事是,两次插入相同的键会覆盖它。这始终会在集合和有序集合中发生,但在包或重复包中不会发生。如果您想避免这种情况,ets:insert_new/2 函数可能就是您想要的,因为它只会在元素不存在于表中时才插入元素。
注意: ETS 表中的元组不必都具有相同的尺寸,尽管这被视为最佳实践。但是,元组的尺寸必须至少与键位置相同(或更大)。
如果您只需要获取元组的一部分,则可以使用另一个查找函数。该函数是 lookup_element(TableID, Key, PositionToReturn),它将返回匹配的元素(或如果包或重复包表中有多个元素,则返回它们的列表)。如果元素不存在,则函数会以 badarg 作为原因出错。
无论如何,让我们再尝试一下包。
9> TabId = ets:new(ingredients, [bag]).
16401
10> ets:insert(TabId, {bacon, delicious}).
true
11> ets:insert(TabId, {bacon, fat}).
true
12> ets:insert(TabId, {bacon, fat}).
true
13> ets:lookup(TabId, bacon).
[{bacon,delicious},{bacon,fat}]
由于这是一个包,因此 {bacon, fat} 尽管我们插入了两次,但只存在一次,但是您可以看到我们仍然可以拥有多个 'bacon' 条目。这里要关注的另一件事是,如果没有传入 named_table 选项,我们就必须使用 TableId 来使用该表。
注意: 如果在复制这些示例时 shell 崩溃,那么表将消失,因为它们的父进程(shell)已经消失。
我们可以利用的最后一些基本操作将是逐个遍历表。如果您注意的话,ordered_set 表最适合这种情况。
14> ets:new(ingredients, [ordered_set, named_table]).
ingredients
15> ets:insert(ingredients, [{ketchup, "not much"}, {mustard, "a lot"}, {cheese, "yes", "goat"}, {patty, "moose"}, {onions, "a lot", "caramelized"}]).
true
16> Res1 = ets:first(ingredients).
cheese
17> Res2 = ets:next(ingredients, Res1).
ketchup
18> Res3 = ets:next(ingredients, Res2).
mustard
19> ets:last(ingredients).
patty
20> ets:prev(ingredients, ets:last(ingredients)).
onions
如您所见,元素现在按排序顺序排列,并且可以从前往后、从后往前逐个访问。哦,对了,然后我们需要看看边界条件下会发生什么。
21> ets:next(ingredients, ets:last(ingredients)). '$end_of_table' 22> ets:prev(ingredients, ets:first(ingredients)). '$end_of_table'
当您看到以 $ 开头的原子时,您应该知道它们是 OTP 团队用来告诉您某些事情的某些特殊值(按惯例选择)。无论何时您尝试在表之外进行迭代,您都会看到这些 $end_of_table 原子。
因此,我们知道如何使用 ETS 作为非常基本的键值存储。现在还有更高级的用法,当我们需要不仅仅是根据键匹配时。
匹配您的匹配

在使用 ETS 从更多特殊机制中查找记录时,有许多函数可用。
当我们考虑它时,选择事物的最佳方式是使用模式匹配,对吧?理想情况是能够以某种方式将要匹配的模式存储在一个变量(或数据结构)中,将其传递给某个 ETS 函数,并让该函数执行其操作。
这称为高阶模式匹配,遗憾的是,Erlang 中没有提供。事实上,很少有语言提供。相反,Erlang 有一些 Erlang 程序员已经同意的某种子语言,用于将模式匹配描述为一堆常规数据结构。
这种表示法基于元组,以很好地适应 ETS。它只是让您指定变量(常规变量和“不关心”变量),这些变量可以与元组混合使用以进行模式匹配。变量写为 '$0'、'$1'、'$2' 等等(数字除了在您将如何获得结果方面没有意义),用于常规变量。“不关心”变量可以写为 '_'。所有这些原子都可以以元组的形式出现,例如
{items, '$3', '$1', '_', '$3'}
这大致等同于使用常规模式匹配来说 {items, C, A, _, C}。因此,您可以猜测第一个元素必须是原子 items,元组的第二个和第五个槽位必须相同,等等。
为了在更实用的环境中使用这种表示法,可以使用两个函数:match/2 和 match_object/2(也提供 match/3 和 match_object/3,但它们的用法超出了本章的范围,建议读者查看文档以获取详细信息)。前者将返回模式的变量,而后者将返回与模式匹配的整个条目。
1> ets:new(table, [named_table, bag]).
table
2> ets:insert(table, [{items, a, b, c, d}, {items, a, b, c, a}, {cat, brown, soft, loveable, selfish}, {friends, [jenn,jeff,etc]}, {items, 1, 2, 3, 1}]).
true
3> ets:match(table, {items, '$1', '$2', '_', '$1'}).
[[a,b],[1,2]]
4> ets:match(table, {items, '$114', '$212', '_', '$6'}).
[[d,a,b],[a,a,b],[1,1,2]]
5> ets:match_object(table, {items, '$1', '$2', '_', '$1'}).
[{items,a,b,c,a},{items,1,2,3,1}]
6> ets:delete(table).
true
match/2-3 作为函数的一个好处是,它只返回严格必须返回的内容。这很有用,因为如前所述,ETS 表遵循无共享的理念。如果您有非常大的记录,那么只复制必要的字段可能是一件好事。无论如何,您还会注意到,虽然变量中的数字没有明确的含义,但它们的顺序很重要。在返回的最终值列表中,绑定到 $114 的值始终在绑定到 $6 的值之后。如果没有任何匹配,则返回空列表。
您可能还想根据这种模式匹配删除条目。在这些情况下,ets:match_delete(Table, Pattern) 函数就是您想要的。

这很好,让我们能够以一种奇怪的方式将任何类型的值用于基本模式匹配。如果能够像比较和范围一样,以显式的方式格式化输出(也许列表不是我们想要的),等等,那就太好了。哦,等等,你可以!
您已被选中
这就是我们获得与真正的函数头级模式匹配等效的东西的时候,包括非常简单的守卫。如果您以前使用过 SQL 数据库,您可能已经看到过执行查询的方法,在这些查询中,您可以比较大于、等于、小于等的其他元素的元素。这就是我们在这里想要的那种好东西。
Erlang 背后的那些人因此采用了我们已经看到的匹配语法,并以疯狂的方式对其进行了扩展,直到它变得足够强大。遗憾的是,他们也让它变得难以阅读。以下是它的样子
[{{'$1','$2',<<1>>,'$3','$4'},
[{'andalso',{'>','$4',150},{'<','$4',500}},
{'orelse',{'==','$2',meat},{'==','$2',dairy}}],
['$1']},
{{'$1','$2',<<1>>,'$3','$4'},
[{'<','$3',4.0},{is_float,'$3'}],
['$1']}]
这很丑,不是你想要让你的孩子看起来像的数据结构。信不信由你,我们将学习如何编写这些叫做匹配规范的东西。不是以那种形式,不,那会毫无道理地太难了。但是,我们仍然会学习如何阅读它们!以下是它从更高层次的角度看起来的样子
[{InitialPattern1, Guards1, ReturnedValue1},
{InitialPattern2, Guards2, ReturnedValue2}].
或者从更高的角度来看
[Clause1, Clause2]
所以是的,像这样的东西大致代表函数头中的模式,然后是守卫,然后是函数的主体。格式仍然限于用于初始模式的 '$N' 变量,与用于匹配函数的变量完全相同。新的部分是守卫模式,允许做一些与常规守卫非常相似的事情。如果我们仔细观察守卫 [{'<','$3',4.0},{is_float,'$3'}],我们可以看到它与 ... when Var < 4.0, is_float(Var) -> ... 作为守卫非常相似。
下一个守卫,这次更复杂,是
[{'andalso',{'>','$4',150},{'<','$4',500}},
{'orelse',{'==','$2',meat},{'==','$2',dairy}}]
将其翻译后,我们得到一个看起来像 ... when Var4 > 150 andalso Var4 < 500, Var2 == meat orelse Var2 == dairy -> ... 的守卫。明白了?
每个操作符或守卫函数都使用前缀语法,这意味着我们使用 {FunctionOrOperator, Arg1, ..., ArgN} 的顺序。因此 is_list(X) 变成 {is_list, '$1'},X andalso Y 变成 {'andalso', X, Y},等等。保留字(如 andalso、orelse)和像 == 这样的操作符需要放到原子中,这样 Erlang 解析器就不会卡住。
模式的最后一部分是您想要返回的内容。只需将您需要的变量放在那里。如果您想要返回匹配规范的完整输入,请使用变量 '$_' 来完成。您可以在 Erlang 文档中找到匹配规范的完整规范。
正如我之前所说,我们不会学习如何以这种方式编写模式,有一种更好的方法。ETS 带有称为解析转换的东西。解析转换是 OTP 团队没有记录(因此不支持)的一种访问编译阶段中途的 Erlang 解析树的方法。它们允许胆大的 Erlang 程序员将模块中的代码转换为新的替代形式。解析转换几乎可以是任何东西,并将现有的 Erlang 代码更改为几乎任何其他东西,只要它不改变语言的语法或令牌。
与 ETS 一起提供的解析转换需要为每个需要它的模块手动启用。在模块中执行此操作的方法如下
-module(SomeModule).
-include_lib("stdlib/include/ms_transform.hrl").
...
some_function() ->
ets:fun2ms(fun(X) when X > 4 -> X end).
-include_lib("stdlib/include/ms_transform.hrl"). 这行包含一些特殊代码,当在模块中使用 ets:fun2ms(SomeLiteralFun) 时,它将覆盖该代码的含义。解析转换不是高阶函数,它将分析 fun 中的内容(模式、守卫和返回值),删除对 ets:fun2ms/1 的函数调用,并将其全部替换为实际的匹配规范。奇怪吧?最好的是,因为这是在编译时发生的,所以使用这种方法没有开销。
我们可以在 shell 中尝试一下,这次不使用包含文件
1> ets:fun2ms(fun(X) -> X end).
[{'$1',[],['$1']}]
2> ets:fun2ms(fun({X,Y}) -> X+Y end).
[{{'$1','$2'},[],[{'+','$1','$2'}]}]
3> ets:fun2ms(fun({X,Y}) when X < Y -> X+Y end).
[{{'$1','$2'},[{'<','$1','$2'}],[{'+','$1','$2'}]}]
4> ets:fun2ms(fun({X,Y}) when X < Y, X rem 2 == 0 -> X+Y end).
[{{'$1','$2'},
[{'<','$1','$2'},{'==',{'rem','$1',2},0}],
[{'+','$1','$2'}]}]
5> ets:fun2ms(fun({X,Y}) when X < Y, X rem 2 == 0; Y == 0 -> X end).
[{{'$1','$2'},
[{'<','$1','$2'},{'==',{'rem','$1',2},0}],
['$1']},
{{'$1','$2'},[{'==','$2',0}],['$1']}]
所有这些!现在它们写起来很容易了!当然,funs 更容易阅读。那么,开头部分那个复杂的例子呢?以下是它作为 fun 的样子
6> ets:fun2ms(fun({Food, Type, <<1>>, Price, Calories}) when Calories > 150 andalso Calories < 500, Type == meat orelse Type == dairy; Price < 4.00, is_float(Price) -> Food end).
[{{'$1','$2',<<1>>,'$3','$4'},
[{'andalso',{'>','$4',150},{'<','$4',500}},
{'orelse',{'==','$2',meat},{'==','$2',dairy}}],
['$1']},
{{'$1','$2',<<1>>,'$3','$4'},
[{'<','$3',4.0},{is_float,'$3'}],
['$1']}]
乍一看它并不完全有意义,但至少当变量可以有名称而不是数字时,弄清楚它的含义要容易得多。要注意的一件事是,并非所有 funs 都是有效的匹配规范
7> ets:fun2ms(fun(X) -> my_own_function(X) end).
Error: fun containing the local function call 'my_own_function/1' (called in body) cannot be translated into match_spec
{error,transform_error}
8> ets:fun2ms(fun(X,Y) -> ok end).
Error: ets:fun2ms requires fun with single variable or tuple parameter
{error,transform_error}
9> ets:fun2ms(fun([X,Y]) -> ok end).
Error: ets:fun2ms requires fun with single variable or tuple parameter
{error,transform_error}
10> ets:fun2ms(fun({<<X/binary>>}) -> ok end).
Error: fun head contains bit syntax matching of variable 'X', which cannot be translated into match_spec
{error,transform_error}
函数头需要匹配单个变量或元组,不能在返回值中调用任何非守卫函数,不允许从二进制文件中分配值,等等。在 shell 中尝试一下,看看你能做什么。
不要喝太多酷乐 aid
一个像 ets:fun2ms 这样的函数听起来棒极了,对吧!不过你要小心使用它。它存在一个问题,那就是虽然在 Shell 中 ets:fun2ms 可以处理动态函数(你可以传递函数,它会直接处理),但编译后的模块中就不行了。
这是因为 Erlang 有两种函数:Shell 函数和模块函数。模块函数会被编译成虚拟机能够识别的紧凑格式。它们是不透明的,无法被检查内部结构。
另一方面,Shell 函数是尚未评估的抽象项。它们以一种允许 Shell 对其调用评估器的方式创建。因此,fun2ms 函数将有两个版本:一个用于获取编译代码,另一个用于在 Shell 中使用。
这没什么问题,只是这些函数不能互相替换。这意味着你不能在 Shell 中获取一个编译后的函数并尝试对其调用 ets:fun2ms,也不能获取一个动态函数并将其发送到一个调用 fun2ms 的编译代码块中。太可惜了!
为了使匹配规范有用,使用它们是有意义的。可以通过使用 ets:select/2 获取结果,ets:select_reverse/2 在 ordered_set 表中反向获取结果(对于其他类型,它与 select/2 相同),ets:select_count/2 了解有多少结果匹配规范,以及 ets:select_delete(Table, MatchSpec) 删除匹配匹配规范的记录。
让我们试试,首先定义一个用于表格的记录,然后用各种商品填充它们。
11> rd(food, {name, calories, price, group}).
food
12> ets:new(food, [ordered_set, {keypos,#food.name}, named_table]).
food
13> ets:insert(food, [#food{name=salmon, calories=88, price=4.00, group=meat},
13> #food{name=cereals, calories=178, price=2.79, group=bread},
13> #food{name=milk, calories=150, price=3.23, group=dairy},
13> #food{name=cake, calories=650, price=7.21, group=delicious},
13> #food{name=bacon, calories=800, price=6.32, group=meat},
13> #food{name=sandwich, calories=550, price=5.78, group=whatever}]).
true
然后我们可以尝试选择卡路里数低于给定值的食品。
14> ets:select(food, ets:fun2ms(fun(N = #food{calories=C}) when C < 600 -> N end)).
[#food{name = cereals,calories = 178,price = 2.79,group = bread},
#food{name = milk,calories = 150,price = 3.23,group = dairy},
#food{name = salmon,calories = 88,price = 4.0,group = meat},
#food{name = sandwich,calories = 550,price = 5.78,group = whatever}]
15> ets:select_reverse(food, ets:fun2ms(fun(N = #food{calories=C}) when C < 600 -> N end)).
[#food{name = sandwich,calories = 550,price = 5.78,group = whatever},
#food{name = salmon,calories = 88,price = 4.0,group = meat},
#food{name = milk,calories = 150,price = 3.23,group = dairy},
#food{name = cereals,calories = 178,price = 2.79,group = bread}]
或者也许我们想要的只是美味的食物。
16> ets:select(food, ets:fun2ms(fun(N = #food{group=delicious}) -> N end)).
[#food{name = cake,calories = 650,price = 7.21,group = delicious}]
删除有一个小技巧。你必须在模式中返回 true,而不是任何类型的值。
17> ets:select_delete(food, ets:fun2ms(fun(#food{price=P}) when P > 5 -> true end)).
3
18> ets:select_reverse(food, ets:fun2ms(fun(N = #food{calories=C}) when C < 600 -> N end)).
[#food{name = salmon,calories = 88,price = 4.0,group = meat},
#food{name = milk,calories = 150,price = 3.23,group = dairy},
#food{name = cereals,calories = 178,price = 2.79,group = bread}]
如最后一个选择所示,超过 5.00 美元的商品已从表格中删除。
ETS 内部还有更多函数,例如将表格转换为列表或文件的方式(ets:tab2list/1、ets:tab2file/1、ets:file2tab/1),获取所有表格的信息(ets:i/0、ets:info(Table))。在这种情况下,强烈建议访问官方文档。
还有一个名为 observer 的应用程序,它有一个选项卡,可用于在给定的 Erlang VM 上直观地管理 ETS 表格。如果你使用 wx 支持构建了 Erlang,只需调用 observer:start() 并选择表格查看器选项卡。在较旧的 Erlang 版本中,observer 不存在,你可能需要使用现在已弃用的 tv 应用程序(tv:start())。
DETS
DETS 是 ETS 的一个基于磁盘的版本,有一些关键区别。
不再有 ordered_set 表格,DETS 文件的磁盘大小限制为 2GB,并且 prev/1 和 next/1 等操作不再像以前那么安全或快速。
启动和停止表格已经改变了一些。通过调用 dets:open_file/2 创建一个新的数据库表格,并通过 dets:close/1 关闭。该表格可以稍后通过调用 dets:open_file/1 重新打开。
否则,API 几乎相同,因此可以采用一种非常简单的方法来处理文件内部数据的写入和查找。
不要喝太多酷乐 aid
DETS 有可能很慢,因为它是一个只使用磁盘的数据库。你可能会想将 ETS 和 DETS 表格组合成一个效率更高的数据库,该数据库将数据存储在 RAM 和磁盘上。
如果你想这样做,最好看看 Mnesia 作为数据库,它做的事情完全相同,但同时增加了对分片、事务和分布的支持。
少说点,多做点

在这样一长串的标题(和前面冗长的部分)之后,我们将回到让我们来到这里的实际问题:更新 regis,使其使用 ETS 并消除一些潜在的瓶颈。
在我们开始之前,我们必须考虑如何处理操作,哪些是安全的操作,哪些是不安全的。安全的操作应该是不修改任何内容且仅限于一次查询(而不是 3-4 次)。它们可以随时由任何人执行。所有涉及写入表格、更新记录、删除记录或以需要在多次请求中保持一致性的方式读取的操作都应视为不安全的。
由于 ETS 没有任何事务,所有不安全的操作都应该由拥有表格的进程执行。安全的操作应该允许公开,在拥有表格的进程之外执行。在更新 regis 时,我们将牢记这一点。
第一步是将 regis-1.0.0 复制为 regis-1.1.0。我在这里增加第二个数字而不是第三个数字,因为我们的更改不应该破坏现有的接口,从技术上来说不是错误修复,所以我们只将其视为功能升级。
在那个新目录中,我们首先只需要操作 regis_server.erl:我们将保持接口完整,因此就结构而言,其他部分不需要做太多改变。
%%% The core of the app: the server in charge of tracking processes.
-module(regis_server).
-behaviour(gen_server).
-include_lib("stdlib/include/ms_transform.hrl").
-export([start_link/0, stop/0, register/2, unregister/1, whereis/1,
get_names/0]).
-export([init/1, handle_call/3, handle_cast/2, handle_info/2,
code_change/3, terminate/2]).
%%%%%%%%%%%%%%%%%
%%% INTERFACE %%%
%%%%%%%%%%%%%%%%%
start_link() ->
gen_server:start_link({local, ?MODULE}, ?MODULE, [], []).
stop() ->
gen_server:call(?MODULE, stop).
%% Give a name to a process
register(Name, Pid) when is_pid(Pid) ->
gen_server:call(?MODULE, {register, Name, Pid}).
%% Remove the name from a process
unregister(Name) ->
gen_server:call(?MODULE, {unregister, Name}).
%% Find the pid associated with a process
whereis(Name) -> ok.
%% Find all the names currently registered.
get_names() -> ok.
对于公共接口,只有 whereis/1 和 get_names/0 会改变并被重写。这是因为如前所述,它们是单一读取安全操作。其余操作需要在拥有表格的进程中进行序列化。这就是到目前为止的 API。让我们进入模块内部。
我们将使用 ETS 表格来存储内容,因此将该表格放入 init 函数是有意义的。此外,因为我们的 whereis/1 和 get_names/0 函数将提供对表格的公共访问权限(为了速度),命名表格对于外部世界访问它来说是必要的。通过命名表格,就像我们命名进程一样,我们可以将名称硬编码到函数中,而不需要传递一个 id。
%%%%%%%%%%%%%%%%%%%%%%%%%%%%
%%% GEN_SERVER CALLBACKS %%%
%%%%%%%%%%%%%%%%%%%%%%%%%%%%
init([]) ->
?MODULE = ets:new(?MODULE, [set, named_table, protected]),
{ok, ?MODULE}.
下一个函数将是 handle_call/3,它处理 {register, Name, Pid} 消息,如 register/2 中定义的那样。
handle_call({register, Name, Pid}, _From, Tid) ->
%% Neither the name or the pid can already be in the table
%% so we match for both of them in a table-long scan using this.
MatchSpec = ets:fun2ms(fun({N,P,_Ref}) when N==Name; P==Pid -> {N,P} end),
case ets:select(Tid, MatchSpec) of
[] -> % free to insert
Ref = erlang:monitor(process, Pid),
ets:insert(Tid, {Name, Pid, Ref}),
{reply, ok, Tid};
[{Name,_}|_] -> % maybe more than one result, but name matches
{reply, {error, name_taken}, Tid};
[{_,Pid}|_] -> % maybe more than one result, but Pid matches
{reply, {error, already_named}, Tid}
end;
这是模块中最复杂的函数。有三个基本规则需要遵守
- 一个进程不能被注册两次。
- 一个名称不能被占用两次。
- 一个进程可以被注册,如果它不违反规则 1 和 2。
上面的代码就是这么做的。从 fun({N,P,_Ref}) when N==Name; P==Pid -> {N,P} end 派生的匹配规范将在整个表格中查找与我们尝试注册的名称或 pid 相匹配的条目。如果找到匹配项,我们将返回找到的名称和 pid。这可能很奇怪,但在我们查看之后 case ... of 的模式时,这是有意义的。
第一个模式意味着没有找到任何匹配项,因此插入是好的。我们监控已注册的进程(以便在进程失败时将其注销),然后将条目添加到表格中。如果我们尝试注册的名称已经存在于表格中,模式 [{Name,_}|_] 将处理它。如果匹配的是 Pid,那么模式 [{_,Pid}|_] 将处理它。这就是为什么返回两个值:它使以后在整个元组上匹配变得更简单,而不关心它们中的哪一个在匹配规范中匹配。为什么模式是 [Tuple|_] 而不是 [Tuple]?解释很简单。如果我们遍历表格寻找类似的 Pid 或名称,返回的列表可能是 [{NameYouWant, SomePid},{SomeName,PidYouWant}]。如果发生这种情况,则 [Tuple] 形式的模式匹配将使负责表格的进程崩溃,并毁掉你的一天。
哦,别忘了在模块中添加 -include_lib("stdlib/include/ms_transform.hrl").,否则 fun2ms 会以奇怪的错误消息退出。
** {badarg,{ets,fun2ms,
[function,called,with,real,'fun',should,be,transformed,with,
parse_transform,'or',called,with,a,'fun',generated,in,the,
shell]}}
这就是忘记包含文件时会发生的事情。当你过马路时要看看,不要跨越溪流,也不要忘记包含文件。
接下来要做的部分是,当我们要求手动注销一个进程时。
handle_call({unregister, Name}, _From, Tid) ->
case ets:lookup(Tid, Name) of
[{Name,_Pid,Ref}] ->
erlang:demonitor(Ref, [flush]),
ets:delete(Tid, Name),
{reply, ok, Tid};
[] ->
{reply, ok, Tid}
end;
如果你看旧版本的代码,这仍然很相似。思路很简单:找到监控引用(通过名称查找),取消监控,然后删除条目并继续。如果条目不存在,我们假装已经删除了它,这样每个人都会很高兴。哦,我们真是太不诚实了。
接下来是关于停止服务器的。
handle_call(stop, _From, Tid) ->
%% For the sake of being synchronous and because emptying ETS
%% tables might take a bit longer than dropping data structures
%% held in memory, dropping the table here will be safer for
%% tricky race conditions, especially in tests where we start/stop
%% servers a lot. In regular code, this doesn't matter.
ets:delete(Tid),
{stop, normal, ok, Tid};
handle_call(_Event, _From, State) ->
{noreply, State}.
如代码中的注释所说,我们可以忽略表格并让它被垃圾回收。但是,由于我们为上一章编写的测试套件一直在启动和停止服务器,因此延迟可能有点危险。看,这是旧服务器的进程时间轴:
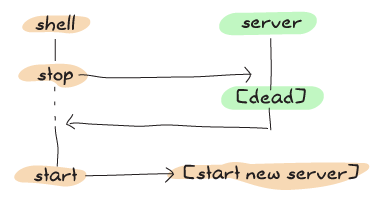
而这是新服务器有时会发生的情况:
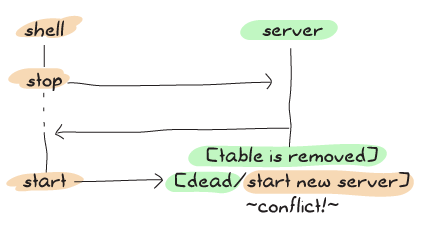
通过使用上述方案,我们通过在代码的同步部分做更多工作来降低发生错误的可能性。
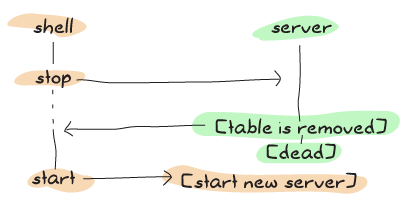
如果你不打算经常运行测试套件,你可以直接忽略整个部分。我决定展示它以避免不愉快的事情,虽然在非测试系统中,这种边缘情况应该很少发生。
以下是其余的 OTP 回调:
handle_cast(_Event, State) ->
{noreply, State}.
handle_info({'DOWN', Ref, process, _Pid, _Reason}, Tid) ->
ets:match_delete(Tid, {'_', '_', Ref}),
{noreply, Tid};
handle_info(_Event, State) ->
{noreply, State}.
code_change(_OldVsn, State, _Extra) ->
{ok, State}.
terminate(_Reason, _State) ->
ok.
我们不关心其中任何一个,除了接收 DOWN 消息,这意味着我们监控的某个进程死掉了。当这种情况发生时,我们根据消息中的引用删除条目,然后继续执行。
你会注意到 code_change/3 实际上可以作为旧 regis_server 和新 regis_server 之间的过渡。实现这个函数留作练习,供读者参考。我一直讨厌那些不提供解决方案就给读者留作业的书籍,所以至少给出一个提示,这样我就不像其他作家那样混蛋:你必须从旧版本中获取两个 gb_trees 中的一个,然后使用 gb_trees:map/2 或 gb_trees 迭代器来填充一个新表格,然后再继续。降级函数可以通过做相反的操作来编写。
剩下的就是修复我们之前未实现的两个公共函数。当然,我们可以写一个 %% TODO 注释,然后就完事了,去喝酒直到忘记自己是程序员,但这会有点不负责任。让我们修复一下。
%% Find the pid associated with a process
whereis(Name) ->
case ets:lookup(?MODULE, Name) of
[{Name, Pid, _Ref}] -> Pid;
[] -> undefined
end.
这个函数查找一个名称,根据条目是否找到返回 Pid 或 undefined。请注意,我们确实在那里使用 regis_server(?MODULE)作为表格名称;这就是为什么我们最初将其设为受保护的并命名的原因。对于下一个函数
%% Find all the names currently registered.
get_names() ->
MatchSpec = ets:fun2ms(fun({Name, _, _}) -> Name end),
ets:select(?MODULE, MatchSpec).
我们再次使用 fun2ms 来匹配 Name 并只保留它。从表格中选择将返回一个列表并完成我们需要的操作。
就是这样!你可以在 test/ 中运行测试套件来执行操作。
$ erl -make ... Recompile: src/regis_server $ erl -pa ebin ... 1> eunit:test(regis_server). All 13 tests passed. ok
太棒了。我想我们现在可以认为自己很擅长使用 ETS 了。
你知道接下来做什么会很棒吗?实际上探索 Erlang 的分布式方面。也许在结束 Erlang 兽之旅之前,我们可以用更多扭曲的方式锻炼一下我们的思维。让我们看看。