函数中的语法
模式匹配

现在我们已经有了存储和编译代码的能力,我们可以开始编写更高级的函数了。我们之前编写的函数非常简单,有点平淡无奇。我们会接触到更有趣的东西。我们将要编写的第一个函数需要根据性别以不同的方式问候某人。在大多数语言中,你需要编写类似于以下内容的代码
function greet(Gender,Name)
if Gender == male then
print("Hello, Mr. %s!", Name)
else if Gender == female then
print("Hello, Mrs. %s!", Name)
else
print("Hello, %s!", Name)
end
使用模式匹配,Erlang 为你节省了大量样板代码。在 Erlang 中,类似的函数看起来像这样
greet(male, Name) ->
io:format("Hello, Mr. ~s!", [Name]);
greet(female, Name) ->
io:format("Hello, Mrs. ~s!", [Name]);
greet(_, Name) ->
io:format("Hello, ~s!", [Name]).
我承认,与许多其他语言相比,Erlang 中的打印函数要难看很多,但这并不是重点。这里的主要区别是我们使用模式匹配来定义函数的哪些部分应该被使用,以及同时绑定我们需要的值。无需先绑定值,然后进行比较!所以,与其编写
function(Args)
if X then
Expression
else if Y then
Expression
else
Expression
我们编写
function(X) -> Expression; function(Y) -> Expression; function(_) -> Expression.
以获得类似的结果,但以更声明性的风格。每个 function 声明都被称为一个*函数子句*。函数子句必须用分号 (;) 分隔,并且一起构成一个*函数声明*。一个函数声明算作一个更大的语句,这就是为什么最后一个函数子句以句号结尾的原因。这是一种使用标记来确定工作流程的“有趣”方式,但你会习惯的。至少你最好希望如此,因为没有其他办法!
注意: io:format 的格式化是通过将标记替换为字符串来完成的。用于表示标记的字符是波浪号 (~)。一些标记是内置的,例如 ~n,它将被更改为换行符。大多数其他标记表示格式化数据的方式。函数调用 io:format("~s!~n",["Hello"]). 包括标记 ~s,它接受字符串和比特字符串作为参数,以及 ~n。最终的输出消息将是 "Hello!\n"。另一个广泛使用的标记是 ~p,它将以一种美观的方式打印 Erlang 项(添加缩进和所有内容)。
io:format 函数将在后面的章节中详细介绍,这些章节将更深入地讨论输入/输出,但在此期间,你可以尝试以下调用以查看它们的作用:io:format("~s~n",[<<"Hello">>]), io:format("~p~n",[<<"Hello">>]), io:format("~~~n"), io:format("~f~n", [4.0]), io:format("~30f~n", [4.0])。它们只是所有可能的操作中的一小部分,总的来说,它们看起来有点像许多其他语言中的 printf。如果你等不及关于 I/O 的章节,你可以阅读 在线文档 以了解更多信息。
函数中的模式匹配可以比这更复杂和更强大。你可能还记得几章前,我们可以对列表进行模式匹配以获取头部和尾部。让我们来做一下!创建一个名为 functions 的新模块,我们将在其中编写一些函数来探索我们可用的许多模式匹配途径
-module(functions). -compile(export_all). %% replace with -export() later, for God's sake!
我们将编写的第一个函数是 head/1,它与 erlang:hd/1 的行为完全一样,它接受一个列表作为参数并返回它的第一个元素。它将借助于 cons 运算符 (|) 完成
head([H|_]) -> H.
如果你在 shell 中输入 functions:head([1,2,3,4]).(模块编译后),你就可以预期得到值 '1'。因此,要获取列表的第二个元素,你可以创建以下函数
second([_,X|_]) -> X.
Erlang 将对列表进行解构以进行模式匹配。在 shell 中试试吧!
1> c(functions).
{ok, functions}
2> functions:head([1,2,3,4]).
1
3> functions:second([1,2,3,4]).
2
这可以重复进行,只要你想要,尽管对于成千上万的值来说,这样做是不切实际的。这可以通过编写递归函数来解决,我们稍后会介绍如何编写。现在,让我们专注于更多模式匹配。我们在 入门(真的) 中讨论的自由变量和绑定变量的概念仍然适用于函数:然后,我们可以比较并知道传递给函数的两个参数是否相同。为此,我们将创建一个名为 same/2 的函数,它接受两个参数并判断它们是否相同
same(X,X) ->
true;
same(_,_) ->
false.
就这么简单。在解释函数的工作原理之前,我们将再次回顾一下绑定变量和未绑定变量的概念,以防万一
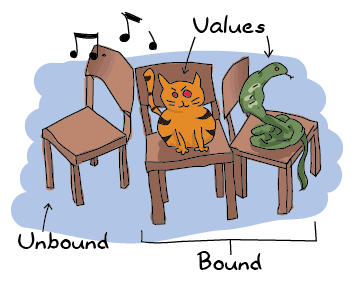
如果这场“音乐椅”游戏是 Erlang,你会想要坐在空椅子上。坐在已经有人坐的椅子上不会有好结果!开个玩笑,未绑定变量是没有绑定任何值的变量(就像我们的空椅子)。绑定变量就是将值附加到未绑定变量上。在 Erlang 的情况下,如果你想将值分配给已经绑定的变量,则会发生错误,*除非新值与旧值相同*。让我们想象一下右边的蛇:如果另一条蛇走过来,对游戏不会有什么改变。你只会得到更多愤怒的蛇。如果另一种动物来坐在椅子上(例如一只蜜獾),事情就会变得糟糕。绑定变量的相同值是可以的,不同的值是不好的。如果你不理解这个概念,可以回到关于 不变变量 的子章节。
回到我们的代码:当你调用 same(a,a) 时,会发生什么情况是,第一个 X 被视为未绑定:它会自动取值 a。然后,当 Erlang 转到第二个参数时,它会看到 X 已经绑定了。然后,它将它与作为第二个参数传递的 a 进行比较,并查看它是否匹配。模式匹配成功,函数返回 true。如果两个值不同,这将失败并转到第二个函数子句,它不关心它的参数(当你最后一个选择时,你就不能挑剔!),而是返回 false。请注意,此函数实际上可以接受任何类型的参数!它适用于任何类型的数据,而不仅仅是列表或单个变量。作为一个相当高级的例子,以下函数打印日期,但只有在日期格式正确的情况下才会打印
valid_time({Date = {Y,M,D}, Time = {H,Min,S}}) ->
io:format("The Date tuple (~p) says today is: ~p/~p/~p,~n",[Date,Y,M,D]),
io:format("The time tuple (~p) indicates: ~p:~p:~p.~n", [Time,H,Min,S]);
valid_time(_) ->
io:format("Stop feeding me wrong data!~n").
请注意,可以在函数头中使用 = 运算符,这允许我们匹配元组 ({Y,M,D}) 内的内容以及元组本身 (Date)。该函数可以按以下方式进行测试
4> c(functions).
{ok, functions}
5> functions:valid_time({{2011,09,06},{09,04,43}}).
The Date tuple ({2011,9,6}) says today is: 2011/9/6,
The time tuple ({9,4,43}) indicates: 9:4:43.
ok
6> functions:valid_time({{2011,09,06},{09,04}}).
Stop feeding me wrong data!
ok
不过,这里有一个问题!这个函数可以接收任何值,甚至是文本或原子,只要元组的形式为 {{A,B,C}, {D,E,F}}。这表明了模式匹配的局限性之一:它可以指定非常精确的值,例如已知的原子数,也可以指定抽象的值,例如列表的头|尾、N 个元素的元组,或者任何东西 (_ 和未绑定变量) 等等。为了解决这个问题,我们使用守卫。
守卫!守卫!
")
守卫是在函数头中可以添加的附加子句,以使模式匹配更具表达力。如上所述,模式匹配在某种程度上是有限的,因为它无法表达诸如值范围或某些数据类型之类的东西。我们无法表示的一个概念是计数:这个 12 岁的篮球运动员是否太矮了,不能与职业球员一起比赛?这段距离是否太长,不能用手走路?你是否太老或太年轻,不能开车?你无法用简单的模式匹配来回答这些问题。我的意思是,你可以表示驾驶问题,例如
old_enough(0) -> false; old_enough(1) -> false; old_enough(2) -> false; ... old_enough(14) -> false; old_enough(15) -> false; old_enough(_) -> true.
但这将是非常不切实际的。如果你愿意,你可以这样做,但你会永远独自工作。如果你想最终交到朋友,创建一个新的 guards 模块,以便我们能够输入驾驶问题的“正确”解决方案
old_enough(X) when X >= 16 -> true; old_enough(_) -> false.
搞定了!正如你所看到的,这要短得多,也更简洁。请注意,守卫表达式的一条基本规则是,它们必须返回 true 才能成功。如果守卫返回 false 或者抛出异常,则该守卫将失败。假设我们现在禁止超过 104 岁的老人开车。我们现在允许驾驶的有效年龄是 16 岁到 104 岁。我们需要处理这个问题,但是怎样呢?我们只需添加第二个守卫子句
right_age(X) when X >= 16, X =< 104 ->
true;
right_age(_) ->
false.
逗号 (,) 的作用类似于运算符 andalso,分号 (;) 的作用类似于 orelse(在“入门(真的)”中描述)。两个守卫表达式都需要成功才能通过整个守卫。我们也可以用相反的方式表示这个函数
wrong_age(X) when X < 16; X > 104 ->
true;
wrong_age(_) ->
false.

我们也得到了正确的结果。如果你想的话,可以测试一下(你应该始终测试东西!)。在守卫表达式中,分号 (;) 的作用类似于 orelse 运算符:如果第一个守卫失败,它就会尝试第二个,然后尝试下一个,直到有一个守卫成功或它们全部失败。
除了比较和布尔值计算之外,你还可以使用一些函数,包括数学运算 (A*B/C >= 0) 和关于数据类型函数,例如 is_integer/1、is_atom/1 等等(我们将在下一章中回顾它们)。守卫的一个缺点是它们不会接受用户定义的函数,因为存在副作用。Erlang 不是一个纯粹的函数式编程语言(例如 Haskell 是的),因为它很大程度上依赖于副作用:你可以执行 I/O、在参与者之间发送消息或者根据需要抛出错误。没有简单的方法可以确定你在守卫中使用的函数是否会打印文本或每次测试都会捕获重要的错误。因此,Erlang 只是不信任你(它这样做可能是正确的!)。
话虽如此,你应该已经足够了解守卫的基本语法,以便在你遇到它们时能够理解它们。
注意:我已经将守卫中的 , 和 ; 与运算符 andalso 和 orelse 进行了比较。不过,它们并不完全相同。前者会捕获它们发生的异常,而后者不会。这意味着,如果在守卫 X >= N; N >= 0 的第一部分中抛出错误,则可以继续评估第二部分,并且守卫可能会成功;如果在守卫 X >= N orelse N >= 0 的第一部分中抛出错误,则第二部分也会被跳过,整个守卫将失败。
但是(总有一个“但是”),只有 andalso 和 orelse 可以在守卫中嵌套。这意味着 (A orelse B) andalso C 是一个有效的守卫,而 (A; B), C 不是。鉴于它们的不同用途,最佳策略通常是根据需要混合使用它们。
什么是 if!?
If 语句就像守卫,并共享守卫的语法,但它存在于函数子句的头部之外。事实上,if 子句被称为*守卫模式*。Erlang 的 if 语句与你在大多数其他语言中遇到的 if 语句不同;与它们相比,它们是奇怪的生物,如果它们有不同的名称,可能会被更多地接受。当你进入 Erlang 的国度时,你应该把所有关于 if 语句的知识都留在门口。坐下来,因为我们要去兜风。
要了解 if 表达式与守卫有多相似,请查看以下示例。
-module(what_the_if).
-export([heh_fine/0]).
heh_fine() ->
if 1 =:= 1 ->
works
end,
if 1 =:= 2; 1 =:= 1 ->
works
end,
if 1 =:= 2, 1 =:= 1 ->
fails
end.
将此保存为 what_the_if.erl 并尝试运行它。
1> c(what_the_if).
./what_the_if.erl:12: Warning: no clause will ever match
./what_the_if.erl:12: Warning: the guard for this clause evaluates to 'false'
{ok,what_the_if}
2> what_the_if:heh_fine().
** exception error: no true branch found when evaluating an if expression
in function what_the_if:heh_fine/0

哦,糟糕!编译器警告我们,第 12 行的 if 语句(1 =:= 2, 1 =:= 1)中的任何子句都不会匹配,因为它的唯一守卫计算结果为 false。请记住,在 Erlang 中,一切都需要返回某些内容,if 表达式也不例外。因此,当 Erlang 无法找到让守卫成功的办法时,它将崩溃:它不能*不*返回某些内容。因此,我们需要添加一个始终成功的通配符分支,无论发生什么情况。在大多数语言中,这将被称为“else”。在 Erlang 中,我们使用“true”(这解释了为什么虚拟机在生气时抛出“未找到 true 分支”)。
oh_god(N) ->
if N =:= 2 -> might_succeed;
true -> always_does %% this is Erlang's if's 'else!'
end.
现在,如果我们测试这个新函数(旧函数将继续发出警告,忽略它们或将它们视为不要这样做的提醒)。
3> c(what_the_if).
./what_the_if.erl:12: Warning: no clause will ever match
./what_the_if.erl:12: Warning: the guard for this clause evaluates to 'false'
{ok,what_the_if}
4> what_the_if:oh_god(2).
might_succeed
5> what_the_if:oh_god(3).
always_does
这里还有另一个函数,展示了如何在 if 表达式中使用多个守卫。该函数还说明了任何表达式都必须返回某些内容:Talk 将 if 表达式的结果绑定到它,然后在一个元组内,在一个字符串中串联起来。在阅读代码时,很容易看出缺乏 true 分支会如何破坏事物,考虑到 Erlang 没有像空值这样的东西(即:Lisp 的 NIL,C 的 NULL,Python 的 None 等)。
%% note, this one would be better as a pattern match in function heads!
%% I'm doing it this way for the sake of the example.
help_me(Animal) ->
Talk = if Animal == cat -> "meow";
Animal == beef -> "mooo";
Animal == dog -> "bark";
Animal == tree -> "bark";
true -> "fgdadfgna"
end,
{Animal, "says " ++ Talk ++ "!"}.
现在我们来试试它。
6> c(what_the_if).
./what_the_if.erl:12: Warning: no clause will ever match
./what_the_if.erl:12: Warning: the guard for this clause evaluates to 'false'
{ok,what_the_if}
7> what_the_if:help_me(dog).
{dog,"says bark!"}
8> what_the_if:help_me("it hurts!").
{"it hurts!","says fgdadfgna!"}
你可能是众多 Erlang 程序员中的一员,他们想知道为什么“true”取代了“else”作为控制流程的原子;毕竟,“else”更熟悉。Richard O'Keefe 在 Erlang 邮件列表中给出了以下答案。我直接引用它,因为我无法表达得更好。
它可能更熟悉,但这并不意味着“else”是件好事。我知道写“; true ->”是在 Erlang 中获得“else”的非常简单的方法,但我们有几十年的编程心理学结果表明这是一个坏主意。我开始替换
by if X > Y -> a() if X > Y -> a() ; true -> b() ; X =< Y -> b() end end if X > Y -> a() if X > Y -> a() ; X < Y -> b() ; X < Y -> b() ; true -> c() ; X ==Y -> c() end end当我_编写_代码时,我发现它有点烦人,但当我_阅读_它时,它非常有用。
“Else”或“true”分支应该完全“避免”:当涵盖所有逻辑结尾而不是依赖于“通配符”子句时,if 语句通常更易于阅读。
如前所述,守卫表达式中只能使用有限的函数集(我们将在类型(或缺乏类型)中看到更多)。这就是 Erlang 的真正条件力量必须发挥作用的地方。我向你展示:case 表达式!
注意:what_the_if.erl 中函数名称所表达的所有这些恐怖,都是针对 if 语言结构而言的,是从其他任何语言的 if 的角度来看的。在 Erlang 的上下文中,它证明是一个完全合乎逻辑的结构,但名称令人困惑。
在 Case ... of 中
如果 if 表达式就像一个守卫,那么 case ... of 表达式就像整个函数头部:你可以拥有与每个参数一起使用的复杂模式匹配,并且你可以在它之上拥有守卫!
由于你可能已经对语法非常熟悉,我们不需要太多示例。对于这个示例,我们将为集合(一组唯一的值)编写追加函数,我们将它们表示为无序列表。这可能是从效率方面来看最糟糕的实现,但我们想要的是语法。
insert(X,[]) ->
[X];
insert(X,Set) ->
case lists:member(X,Set) of
true -> Set;
false -> [X|Set]
end.
如果我们传入一个空集(列表)和一个要添加的项 X,它会返回一个只包含 X 的列表。否则,函数 lists:member/2 检查元素是否为列表的一部分,如果存在则返回 true,如果不存在则返回 false。如果我们已经将元素 X 包含在集合中,则不需要修改列表。否则,我们将 X 添加为列表的第一个元素。
在这种情况下,模式匹配非常简单。它可以变得更复杂(你可以将你的代码与 我的代码 进行比较)。
beach(Temperature) ->
case Temperature of
{celsius, N} when N >= 20, N =< 45 ->
'favorable';
{kelvin, N} when N >= 293, N =< 318 ->
'scientifically favorable';
{fahrenheit, N} when N >= 68, N =< 113 ->
'favorable in the US';
_ ->
'avoid beach'
end.
在这里,关于“现在是否适合去海滩”的答案是在 3 种不同的温度系统中给出的:摄氏度、开尔文和华氏度。模式匹配和守卫相结合,以返回满足所有用途的答案。如前所述,case ... of 表达式与许多带有守卫的函数头部几乎完全相同。事实上,我们可以以以下方式编写我们的代码。
beachf({celsius, N}) when N >= 20, N =< 45 ->
'favorable';
...
beachf(_) ->
'avoid beach'.
这就提出了一个问题:我们应该何时使用 if、case ... of 或函数来执行条件表达式?

该使用哪个?
该使用哪个很难回答。函数调用和 case ... of 之间的区别非常小:事实上,它们在更低的级别以相同的方式表示,并且使用其中任何一个实际上在性能方面具有相同的成本。两者之间的一个区别是,当需要评估多个参数时:function(A,B) -> ... end. 可以具有针对 A 和 B 的守卫和匹配的值,但 case 表达式需要类似于以下形式进行公式化。
case {A,B} of
Pattern Guards -> ...
end.
这种形式很少见,可能会让读者感到惊讶。在类似情况下,使用函数调用可能更合适。另一方面,我们之前编写的 insert/2 函数可以说用它现在的形式更简洁,而不是在简单的 true 或 false 子句上进行直接的函数调用跟踪。
那么另一个问题是,考虑到 case 和函数足够灵活,甚至可以通过守卫包含 if,你为什么还要使用 if?if 背后的理由非常简单:它作为语言的简写方式被添加,用于在不需要编写整个模式匹配部分时具有守卫。
当然,所有这些更多地是关于个人喜好以及你可能更常遇到的内容。没有好的可靠答案。整个主题仍然不时地在 Erlang 社区中进行辩论。只要易于理解,没有人会因为你选择了什么而责怪你。正如沃德·坎宁安曾经说过的那样,"整洁的代码是你查看例程时,它基本上是你所期望的。"