错误和异常
别急!

对于这样的章节,并没有一个合适的位置。到目前为止,你已经学到了足够多的知识,很可能已经遇到了错误,但还不够了解如何处理它们。事实上,在本节中,我们无法看到所有错误处理机制。这是因为 Erlang 有两种主要范式:函数式和并发式。从本书开始,我一直都在解释函数式子集:引用透明、递归、高阶函数等。并发式子集是让 Erlang 闻名于世的:actor、数千甚至上万个并发进程、监督树等。
因为我认为在继续学习并发式部分之前,必须先了解函数式部分,所以本章只涵盖语言的函数式子集。如果要管理错误,我们必须先了解它们。
**注意:**尽管 Erlang 在函数式代码中包含了一些处理错误的方法,但大多数情况下,你会被告知直接让它崩溃。我在介绍中提到了这一点。让你以这种方式编程的机制是在语言的并发式部分。
错误汇编
错误有很多种:编译时错误、逻辑错误、运行时错误和生成错误。在本节中,我将重点介绍编译时错误,并在接下来的部分中介绍其他错误。
编译时错误通常是语法错误:检查你的函数名称、语言中的标记(括号、圆括号、句号、逗号)、函数的元数等。以下是一些常见编译时错误消息列表,以及遇到这些错误时可能的解决方案
- module.beam: 模块名 'madule' 与文件名 'module' 不匹配
- 你在
-module属性中输入的模块名称与文件名不匹配。 - ./module.erl:2: 警告:函数 some_function/0 未使用
- 你没有导出函数,或者使用该函数的位置名称或元数错误。也有可能你写了一个不再需要的函数。检查你的代码!
- ./module.erl:2: 函数 some_function/1 未定义
- 该函数不存在。你在
-export属性中或声明函数时写错了名称或元数。当给定函数无法编译时,也会输出此错误,通常是因为语法错误,例如忘记用句号结束函数。 - ./module.erl:5: 语法错误,在 'SomeCharacterOrWord' 之前
- 这种情况有多种原因,主要包括未闭合的括号、元组或错误的表达式终止(例如,用逗号关闭
case的最后一个分支)。其他原因可能包括在你的代码中使用保留的原子,或者 unicode 字符在不同的编码之间奇怪地转换(我见过这种情况!) - ./module.erl:5: 语法错误,在之前
- 好吧,这个肯定没有那么描述性!这种情况通常发生在你行的终止不正确时。这是前面错误的一个特例,所以注意一下。
- ./module.erl:5: 警告:此表达式将引发 'badarith' 异常
- Erlang 都是关于动态类型的,但请记住,类型是强类型的。在这种情况下,编译器足够智能,可以发现你的算术表达式之一将失败(例如,
llama + 5)。不过,它无法找到比这更复杂的类型错误。 - ./module.erl:5: 警告:变量 'Var' 未使用
- 你声明了一个变量,但之后从未使用它。这可能是你的代码中的错误,所以仔细检查你写了什么。否则,如果你觉得这个名称有助于使代码更易读,你可能想将变量名改为
_或者在前面加上一个下划线(类似于 _Var)。 - ./module.erl:5: 警告:构造了一个项,但从未使用
- 在你的某个函数中,你正在做一些事情,例如构建一个列表、声明一个元组或匿名函数,而从未将它绑定到变量或返回它。此警告告诉你,你正在做一些无用的事情,或者你犯了一些错误。
- ./module.erl:5: 头不匹配
- 你的函数可能有多个头,每个头都有不同的元数。不要忘记,不同的元数意味着不同的函数,你不能以这种方式交错函数声明。当你将函数定义插入另一个函数的头子句之间时,也会引发此错误。
- ./module.erl:5: 警告:此子句无法匹配,因为第 4 行的前面子句总是匹配
- 模块中定义的函数在捕获所有子句之后定义了一个特定的子句。因此,编译器可以警告你,你甚至不需要转到另一个分支。
- ./module.erl:9: 变量 'A' 在 'case' 中不安全(第 5 行)
- 你正在
case ... of的分支中使用其中一个分支中声明的变量。这被认为是不安全的。如果你想使用这些变量,最好这样做MyVar = case ... of...
这应该涵盖了你在编译时遇到的大多数错误。错误并不多,大多数情况下,最难的部分是找到哪个错误导致了针对其他函数列出的大量错误级联。最好按报告的顺序解决编译器错误,以避免被实际上可能不是错误的错误误导。其他类型的错误有时也会出现,如果你遇到我未列出的错误,请给我发邮件,我会尽快添加说明和解释。
不,是你的逻辑错了!

逻辑错误是最难发现和调试的错误。它们最可能是来自程序员的错误:条件语句的分支,如 'if' 和 'case',没有考虑所有情况,将乘法与除法混淆等。它们不会使你的程序崩溃,而是最终会导致你获得看不见的错误数据,或者你的程序以非预期的方式工作。
在这一点上,你很可能只能靠自己,但 Erlang 有许多工具来帮助你,包括测试框架、TypEr 和 Dialyzer(如类型章节中所述)、调试器 和 跟踪模块 等。测试你的代码可能是你最好的防御。不幸的是,每个程序员的职业生涯中都有足够多的这类错误,可以写几十本书来介绍它们,所以我将避免在这里花费太多时间。专注于那些使你的程序崩溃的错误更容易,因为它们会立即发生,并且不会从现在开始向上冒泡 50 级。请注意,这几乎就是我多次提到的“让它崩溃”理念的起源。
运行时错误
运行时错误在某种程度上非常具有破坏性,因为它们会使你的代码崩溃。虽然 Erlang 有方法来处理它们,但识别这些错误总是有帮助的。因此,我列出了常见的运行时错误,并附有解释和可以生成它们的示例代码。
- function_clause
-
1> lists:sort([3,2,1]). [1,2,3] 2> lists:sort(fffffff). ** exception error: no function clause matching lists:sort(fffffff) - 函数的所有守卫子句都失败,或者没有一个函数子句的模式匹配成功。
- case_clause
-
3> case "Unexpected Value" of 3> expected_value -> ok; 3> other_expected_value -> 'also ok' 3> end. ** exception error: no case clause matching "Unexpected Value" - 看起来有人忘记了
case中的特定模式,输入了错误的数据类型,或者需要一个捕获所有子句! - if_clause
-
4> if 2 > 4 -> ok; 4> 0 > 1 -> ok 4> end. ** exception error: no true branch found when evaluating an if expression - 这与
case_clause错误非常相似:它无法找到一个计算结果为true的分支。确保你考虑所有情况或添加捕获所有true子句可能是你需要的。 - badmatch
-
5> [X,Y] = {4,5}. ** exception error: no match of right hand side value {4,5} - 每当模式匹配失败时,就会发生坏匹配错误。这很可能意味着你正在尝试进行不可能的模式匹配(如上所述)、尝试第二次绑定变量,或者只是在
=运算符两侧不等于的东西(这几乎是使变量重新绑定失败的原因!)。请注意,此错误有时发生是因为程序员认为形如 _MyVar 的变量与_相同。带下划线的变量是普通变量,只是编译器不会在不使用它们时报错。不可能将它们绑定多次。 - badarg
-
6> erlang:binary_to_list("heh, already a list"). ** exception error: bad argument in function binary_to_list/1 called as binary_to_list("heh, already a list") - 这个错误与
function_clause非常相似,因为它与使用不正确的参数调用函数有关。这里的主要区别是,此错误通常是在函数内部验证参数后由程序员触发的,而不是在守卫子句之外。我将在本章后面介绍如何抛出此类错误。 - undef
-
7> lists:random([1,2,3]). ** exception error: undefined function lists:random/1 - 当调用不存在的函数时,就会发生这种情况。确保该函数已从模块中导出,并具有正确的元数(如果你从模块外部调用它),并仔细检查你是否正确地输入了函数名称和模块名称。收到此消息的另一个原因是模块不在 Erlang 的搜索路径中。默认情况下,Erlang 的搜索路径设置为当前目录。你可以使用
code:add_patha/1或code:add_pathz/1添加路径。如果仍然不起作用,请确保你已经编译了模块! - badarith
-
8> 5 + llama. ** exception error: bad argument in an arithmetic expression in operator +/2 called as 5 + llama - 当你尝试进行不存在的算术运算时,就会发生这种情况,例如除以零或原子和数字之间的运算。
- badfun
-
9> hhfuns:add(one,two). ** exception error: bad function one in function hhfuns:add/2 - 此错误最常发生的原因是当你将变量用作函数时,但变量的值不是函数。在上面的示例中,我使用的是 上一章 中的
hhfuns函数,并使用两个原子作为函数。这不起作用,并抛出了badfun错误。 - badarity
-
10> F = fun(_) -> ok end. #Fun<erl_eval.6.13229925> 11> F(a,b). ** exception error: interpreted function with arity 1 called with two arguments badarity错误是badfun的一个特例:当使用高阶函数,但传递的参数比它们能处理的更多(或更少)时,就会发生这种情况。- system_limit
system_limit错误可能有很多原因:进程过多(我们将会讲到)、原子过长、函数中的参数过多、原子数量过大、连接的节点过多等。要详细了解完整列表,请阅读Erlang 效率指南中的系统限制。请注意,其中一些错误严重到足以使整个 VM 崩溃。
引发异常

在尝试监控代码执行并防止逻辑错误时,提前引发运行时崩溃通常是一个好主意,这样可以及早发现问题。
Erlang 中有三种异常:错误、抛出和退出。它们都有不同的用途(有点像)
错误
调用 erlang:error(Reason) 将结束当前进程中的执行,并在你捕获它时包含一个包含最后调用的函数及其参数的堆栈跟踪。这些是引发上面运行时错误的异常。
错误是函数在无法预期调用代码处理当前情况时停止执行的一种方式。如果你遇到了一个if_clause 错误,你能做什么?更改代码并重新编译,这是你能做的(除了仅仅显示一个漂亮的错误消息)。不使用错误的一个例子可能是我们从递归章节中得到的树模块。该模块在执行查找时可能无法始终在树中找到特定的键。在这种情况下,期望用户处理未知结果是有意义的:他们可以使用默认值,检查是否要插入新的值,删除树等。此时,返回一个{ok, Value}形式的元组或一个像undefined这样的原子比引发错误更合适。
现在,错误并不局限于上面的例子。你也可以定义你自己的错误类型。
1> erlang:error(badarith). ** exception error: bad argument in an arithmetic expression 2> erlang:error(custom_error). ** exception error: custom_error
这里,custom_error不被 Erlang shell 识别,并且没有像“...中的错误参数”这样的自定义翻译,但它以相同的方式使用,并且可以由程序员以相同的方式处理(我们很快就会看到如何做)。
退出
有两种类型的退出:“内部”退出和“外部”退出。内部退出是通过调用函数exit/1触发的,并使当前进程停止执行。外部退出使用exit/2调用,并且与 Erlang 并发方面中的多个进程有关;因此,我们将主要关注内部退出,并在稍后讨论外部退出。
内部退出与错误非常相似。事实上,从历史上讲,它们是相同的,并且只存在exit/1。它们的用例大体相同。那么如何选择呢?好吧,选择并不明显。要了解何时使用一个或另一个,除了从远处开始观察参与者和进程的概念别无选择。
在介绍中,我将进程比作通过邮件进行通信的人。这个比喻没有太多要补充的,所以我将转向图表和气泡。

这里的进程可以互相发送消息。一个进程也可以监听消息,等待消息。你还可以选择要监听哪些消息,丢弃一些,忽略其他一些,在一定时间后停止监听等。

这些基本概念允许 Erlang 的实现者使用一种特殊类型的消息来在进程之间通信异常。它们有点像一个进程的最后呼吸;它们在进程死亡之前发送,并且它包含的代码停止执行。其他正在监听该特定类型消息的进程可以知道该事件并对其进行任何处理。这包括记录、重启已死亡的进程等。

解释了这个概念后,使用erlang:error/1和exit/1之间的区别就更容易理解了。虽然两者都可以以非常相似的方式使用,但真正的区别在于意图。然后你可以决定你所拥有的是“简单”的错误还是值得杀死当前进程的条件。erlang:error/1返回一个堆栈跟踪,而exit/1不返回堆栈跟踪,这一事实加强了这一点。如果你有一个非常大的堆栈跟踪或当前函数有很多参数,将退出消息复制到每个监听进程将意味着复制数据。在某些情况下,这可能变得不切实际。
抛出
抛出是一种用于程序员可以预期处理的异常类别。与退出和错误相比,它们实际上并不包含任何“崩溃该进程!”的意图,而是控制流程。当你在期望程序员处理它们的情况下使用抛出时,通常最好在使用它们的模块中记录它们的使用。
抛出异常的语法是
1> throw(permission_denied). ** exception throw: permission_denied
你可以用你想要的任何东西替换permission_denied(包括'everything is fine',但这没有帮助,你会失去朋友)。
抛出也可以用于深度递归时的非局部返回。一个例子是ssl模块,它使用throw/1作为一种将{error, Reason}元组推回顶层函数的方式。然后,该函数简单地将该元组返回给用户。这使实现者只需为成功情况编写代码,并让一个函数在所有这些之上处理异常。
另一个例子可能是数组模块,其中有一个查找函数,如果找不到所需的元素,它可以返回用户提供的默认值。当找不到元素时,default值将作为异常抛出,顶层函数处理该异常并将其替换为用户提供的默认值。这使模块的程序员无需将默认值作为查找算法的每个函数的参数传递,再次只关注成功情况。

作为经验法则,尽量将你的抛出用于非局部返回的次数限制在单个模块中,以便于调试代码。它还允许你更改模块的内部结构,而无需更改其接口。
处理异常
我已经多次提到抛出、错误和退出可以处理。实现此操作的方法是使用try ... catch表达式。
try ... catch是一种在评估表达式时允许你处理成功情况以及遇到的错误的方式。这种表达式的通用语法是
try Expression of
SuccessfulPattern1 [Guards] ->
Expression1;
SuccessfulPattern2 [Guards] ->
Expression2
catch
TypeOfError:ExceptionPattern1 ->
Expression3;
TypeOfError:ExceptionPattern2 ->
Expression4
end.
try和of之间的Expression被称为受保护的。这意味着在该调用中发生的任何类型的异常都将被捕获。try ... of和catch之间的模式和表达式与case ... of的行为完全相同。最后是catch部分:在这里,你可以用error、throw或exit替换TypeOfError,分别对应我们在本章中看到的每种类型。如果没有提供类型,则假设为throw。让我们将这些应用到实践中。
首先,让我们启动一个名为exceptions的模块。我们在这里追求简单。
-module(exceptions).
-compile(export_all).
throws(F) ->
try F() of
_ -> ok
catch
Throw -> {throw, caught, Throw}
end.
我们可以编译它并使用不同类型的异常进行尝试
1> c(exceptions).
{ok,exceptions}
2> exceptions:throws(fun() -> throw(thrown) end).
{throw,caught,thrown}
3> exceptions:throws(fun() -> erlang:error(pang) end).
** exception error: pang
如你所见,这个try ... catch只接收抛出。如前所述,这是因为当没有提到类型时,会假设为抛出。然后我们有带有每个类型捕获子句的函数
errors(F) ->
try F() of
_ -> ok
catch
error:Error -> {error, caught, Error}
end.
exits(F) ->
try F() of
_ -> ok
catch
exit:Exit -> {exit, caught, Exit}
end.
并尝试它们
4> c(exceptions).
{ok,exceptions}
5> exceptions:errors(fun() -> erlang:error("Die!") end).
{error,caught,"Die!"}
6> exceptions:exits(fun() -> exit(goodbye) end).
{exit,caught,goodbye}
菜单上的下一个例子展示了如何在单个try ... catch中组合所有类型的异常。我们首先声明一个函数来生成我们需要的所有异常
sword(1) -> throw(slice);
sword(2) -> erlang:error(cut_arm);
sword(3) -> exit(cut_leg);
sword(4) -> throw(punch);
sword(5) -> exit(cross_bridge).
black_knight(Attack) when is_function(Attack, 0) ->
try Attack() of
_ -> "None shall pass."
catch
throw:slice -> "It is but a scratch.";
error:cut_arm -> "I've had worse.";
exit:cut_leg -> "Come on you pansy!";
_:_ -> "Just a flesh wound."
end.
这里is_function/2是一个 BIF,它确保变量Attack是一个元数为 0 的函数。然后我们为了保险起见添加一个函数
talk() -> "blah blah".
现在让我们做点与众不同的事情:
7> c(exceptions).
{ok,exceptions}
8> exceptions:talk().
"blah blah"
9> exceptions:black_knight(fun exceptions:talk/0).
"None shall pass."
10> exceptions:black_knight(fun() -> exceptions:sword(1) end).
"It is but a scratch."
11> exceptions:black_knight(fun() -> exceptions:sword(2) end).
"I've had worse."
12> exceptions:black_knight(fun() -> exceptions:sword(3) end).
"Come on you pansy!"
13> exceptions:black_knight(fun() -> exceptions:sword(4) end).
"Just a flesh wound."
14> exceptions:black_knight(fun() -> exceptions:sword(5) end).
"Just a flesh wound."

第 9 行的表达式演示了黑骑士的正常行为,当函数执行正常发生时。紧随其后的每一行都演示了根据异常的类别(抛出、错误、退出)和与它们相关的理由(slice、cut_arm、cut_leg)对异常进行模式匹配。
这里在第 13 行和第 14 行展示的一个东西是用于异常的捕获所有子句。_:_模式是你需要使用的,以确保捕获任何类型的任何异常。在实践中,在使用捕获所有模式时应该小心:尽量保护你的代码免受你能够处理的内容的影响,但不要超过这个范围。Erlang 有其他机制来处理其余部分。
还可以添加一个额外的子句,该子句可以在try ... catch之后添加,并且始终会执行。这相当于许多其他语言中的“finally”块。
try Expr of
Pattern -> Expr1
catch
Type:Exception -> Expr2
after % this always gets executed
Expr3
end
无论是否出现错误,after部分中的表达式都保证会运行。但是,你无法从after结构中获得任何返回值。因此,after主要用于运行具有副作用的代码。最典型的用法是,当你想要确保你正在读取的文件无论是否抛出异常都会被关闭时。
我们现在知道如何使用捕获块来处理 Erlang 中的 3 种异常类别。但是,我对你隐瞒了一些信息:实际上可以使用try和of之间不止一个表达式!
whoa() ->
try
talk(),
_Knight = "None shall Pass!",
_Doubles = [N*2 || N <- lists:seq(1,100)],
throw(up),
_WillReturnThis = tequila
of
tequila -> "hey this worked!"
catch
Exception:Reason -> {caught, Exception, Reason}
end.
通过调用exceptions:whoa(),我们将获得明显的{caught, throw, up},因为throw(up)。所以是的,可以使用try和of之间不止一个表达式...
我在exceptions:whoa/0中强调的,你可能没有注意到的是,当我们以这种方式使用多个表达式时,我们可能并不总是关心返回值是什么。因此,of部分变得有点没用。好消息是,你可以放弃它
im_impressed() ->
try
talk(),
_Knight = "None shall Pass!",
_Doubles = [N*2 || N <- lists:seq(1,100)],
throw(up),
_WillReturnThis = tequila
catch
Exception:Reason -> {caught, Exception, Reason}
end.
现在它变得简洁了不少!
注意:重要的是要知道异常的受保护部分不能是尾递归的。虚拟机必须始终在那里保留一个引用,以防出现异常。
因为没有of部分的try ... catch结构除了受保护部分之外什么都没有,所以从那里调用递归函数对于应该长时间运行的程序来说可能很危险(这是 Erlang 的利基市场)。经过足够的迭代后,你将耗尽内存,或者你的程序会变得更慢,而你却不知道原因。通过将你的递归调用放在of和catch之间,你就不会处于受保护部分,并且将受益于尾调用优化。
有些人默认情况下使用try ... of ... catch而不是try ... catch,以避免这种类型的意外错误,除了那些明显是非递归的代码,其结果不会被任何东西使用。你很可能能够自己决定要做什么!
等等,还有更多!
好像与大多数语言相比已经足够了,Erlang 还有另一个错误处理结构。该结构被定义为关键字catch,基本上捕获所有类型的异常,以及好的结果。它有点奇怪,因为它显示了异常的不同表示
1> catch throw(whoa).
whoa
2> catch exit(die).
{'EXIT',die}
3> catch 1/0.
{'EXIT',{badarith,[{erlang,'/',[1,0]},
{erl_eval,do_apply,5},
{erl_eval,expr,5},
{shell,exprs,6},
{shell,eval_exprs,6},
{shell,eval_loop,3}]}}
4> catch 2+2.
4
我们可以从这里看到抛出保持不变,但退出和错误都表示为{'EXIT', Reason}。这是因为错误是在退出之后被附加到语言中的(它们为了向后兼容性而保持了类似的表示)。
阅读这个堆栈跟踪的方法如下
5> catch doesnt:exist(a,4).
{'EXIT',{undef,[{doesnt,exist,[a,4]},
{erl_eval,do_apply,5},
{erl_eval,expr,5},
{shell,exprs,6},
{shell,eval_exprs,6},
{shell,eval_loop,3}]}}
- 错误类型为
undef,这意味着你调用的函数未定义(参见本章开头的列表)。 - 错误类型之后的列表是一个堆栈跟踪
- 堆栈跟踪顶部的元组表示最后调用的函数(
{Module, Function, Arguments})。那就是你的未定义函数。 - 后面的元组是调用错误之前的函数。这一次它们的格式为
{Module, Function, Arity}。 - 这就是它的全部内容了。
你也可以通过在崩溃的进程中调用erlang:get_stacktrace/0来手动获取堆栈跟踪。
你经常会看到catch以以下方式编写(我们仍然在exceptions.erl中)。
catcher(X,Y) ->
case catch X/Y of
{'EXIT', {badarith,_}} -> "uh oh";
N -> N
end.
正如预期的那样
6> c(exceptions).
{ok,exceptions}
7> exceptions:catcher(3,3).
1.0
8> exceptions:catcher(6,3).
2.0
9> exceptions:catcher(6,0).
"uh oh"
这听起来很紧凑,而且易于捕获异常,但catch存在一些问题。第一个是运算符优先级
10> X = catch 4+2. * 1: syntax error before: 'catch' 10> X = (catch 4+2). 6
鉴于大多数表达式不需要以这种方式用括号括起来,这并不完全直观。catch的另一个问题是,你无法区分看起来像异常的底层表示和真正的异常
11> catch erlang:boat().
{'EXIT',{undef,[{erlang,boat,[]},
{erl_eval,do_apply,5},
{erl_eval,expr,5},
{shell,exprs,6},
{shell,eval_exprs,6},
{shell,eval_loop,3}]}}
12> catch exit({undef, [{erlang,boat,[]}, {erl_eval,do_apply,5}, {erl_eval,expr,5}, {shell,exprs,6}, {shell,eval_exprs,6}, {shell,eval_loop,3}]}).
{'EXIT',{undef,[{erlang,boat,[]},
{erl_eval,do_apply,5},
{erl_eval,expr,5},
{shell,exprs,6},
{shell,eval_exprs,6},
{shell,eval_loop,3}]}}
而且你无法区分错误和实际退出。你也可以使用throw/1来生成上述异常。事实上,在catch中的throw/1在另一种情况下也可能存在问题
one_or_two(1) -> return; one_or_two(2) -> throw(return).
现在是致命的问题
13> c(exceptions).
{ok,exceptions}
14> catch exceptions:one_or_two(1).
return
15> catch exceptions:one_or_two(2).
return
因为我们在catch后面,我们永远无法知道函数是抛出了异常还是返回了实际值!这在实践中可能不会经常发生,但它仍然是一个足以让 R10B 版本添加try ... catch构造的瑕疵。
在树中尝试一个 try
为了将异常付诸实践,我们将进行一个小的练习,需要我们挖掘我们的tree模块。我们将添加一个函数,让我们可以在树中查找,以了解某个值是否已经存在。由于树按其键排序,在本例中我们不关心键,所以我们需要遍历整个树直到找到该值。
遍历树的过程与我们在tree:lookup/2中所做的类似,只是这次我们始终会在左分支和右分支上向下搜索。为了编写该函数,你只需要记住,树节点要么是{node, {Key, Value, NodeLeft, NodeRight}},要么是{node, 'nil'}(当为空时)。有了这些,我们可以编写一个没有异常的基本实现
%% looks for a given value 'Val' in the tree.
has_value(_, {node, 'nil'}) ->
false;
has_value(Val, {node, {_, Val, _, _}}) ->
true;
has_value(Val, {node, {_, _, Left, Right}}) ->
case has_value(Val, Left) of
true -> true;
false -> has_value(Val, Right)
end.
这个实现的问题是,我们分叉的每个树节点都必须测试上一个分支的结果
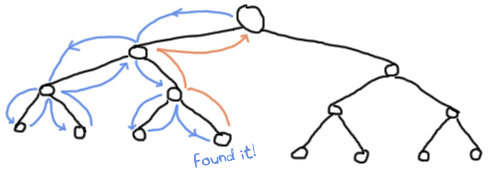
这有点烦人。借助 throws,我们可以创建一个需要更少比较的程序
has_value(Val, Tree) ->
try has_value1(Val, Tree) of
false -> false
catch
true -> true
end.
has_value1(_, {node, 'nil'}) ->
false;
has_value1(Val, {node, {_, Val, _, _}}) ->
throw(true);
has_value1(Val, {node, {_, _, Left, Right}}) ->
has_value1(Val, Left),
has_value1(Val, Right).
上面代码的执行与之前的版本类似,只是我们不需要检查返回值:我们根本不关心它。在这个版本中,只有 throw 表示找到了值。当这种情况发生时,树的评估停止,并回退到上面的catch。否则,执行将一直进行,直到最后一个false被返回,这就是用户看到的结果
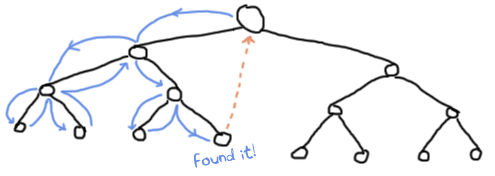
当然,上面的实现比之前的实现更长。但是,通过使用带有 throw 的非局部返回,可以实现速度和清晰度的提升,这取决于你正在执行的操作。当前的示例只是一个简单的比较,并没有太多可看的东西,但这种做法在更复杂的数据结构和操作中仍然是有意义的。
话虽如此,我们可能已经准备好解决顺序式 Erlang 中的实际问题了。